3 R code for Regression Analysis
The goal of this chapter is to have you learn to use R to carry out the analyses and techniques generally covered in a regression analysis course. Currently, we carry out some of the examples using R found in
Kutner M.H, Nachtsheim C.J, and Neter, J., Applied Linear Regression Models. McGraw-Hill/Irwin.
The abbreviation ALRM is used for this textbook. Datasets for this textbook may be found at
https://www.csub.edu/~emontoya2/datasets/textbookdata/index.html
3.1 Linear Regression with One Predictor Variable
In this section, we use R to fit the simple linear regression (SLM) model \[ y_i=\beta_0+\beta_1 x_i + \varepsilon_i \] where \(y_i\) is the dependent/response variable, \(x_i\) is the independent/predictor variable, and the random error terms have mean 0, constant variance \(\sigma^2\) and are uncorrelated. We follow the Toluca Company example given in ALRM to illustrate how to use R to obtain scatter plots, the least square estimates, fitted values, residuals, and a point estimator of \(\sigma^2\).
3.1.1 Scatterplots
Scatterplots can be used to explore the relationship between two variables. Recall that the formula to create a graphical numerical summary follows the general form goal( ~ x , data) where x is the variable you want to graph. However, now we have an additional variable. When the data is bivariate the general formula changes a bit: goal( y ~ x , data ), where y is the name of the response/dependent variable and x is the name of the explanatory/predictor variable. To create a scatterplot, goal is replaced with xyplot.
We begin by importing the data:
require( mosaic ) # always load the mosaic package first.
### The datasets from the book are available to download or
### read from a url, but we have to make some changes
### to read.csv() because these files are not csv files.
### Import data:
url <- "http://www.csub.edu/~emontoya2/datasets/textbookdata/Kutner/Chapter%20%201%20Data%20Sets/CH01TA01.txt"
### Use this as a template for importing datasets referenced
### in the textbook.
### This is not a .csv file and the file does not
### include variable names, so some changes
### have to be made to read.csv().
toluca.data <- read.csv( url , header = FALSE , col.names = c("xvar", "yvar") , sep = "" )We can take a quick look at the data by using glimpse( ):
glimpse( toluca.data )
#> Rows: 25
#> Columns: 2
#> $ xvar <int> 80, 30, 50, 90, 70, 60, 120, 80, 100, 50, 40, 70, 90, 20, 110, 10~
#> $ yvar <int> 399, 121, 221, 376, 361, 224, 546, 352, 353, 157, 160, 252, 389, ~Note that we named the response variable and explanatory variable \(yvar\) and \(xvar\), respectively. So these names must be used in xyplot( ) or any other function that uses toluca.data:
xyplot( yvar ~ xvar , data= toluca.data)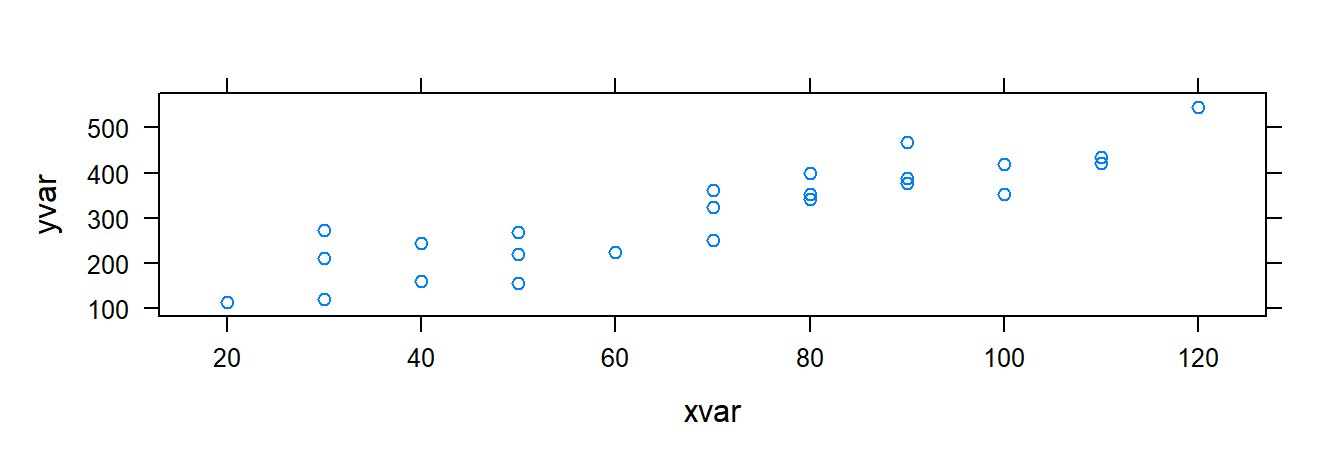
The function xyplot( ) has other arguments that allows you to change label axis, add a title, etc.:
### xyplot( y ~ x | gfactor, data, main, xlab, ylab, col, pch)
# y: respnose variable
# x: explanatory variable
# gfactor: a factor variable (optional) so that a plot is returned for each level of f1 (optional)
# data: the name of the dataframe where the observed data is found
# main: title for plot (optional)
# ylab: label for y-axis (optional)
# xlab: label for x-axis (optional)
# pch: point symbol. Must be a number between 1-25 (optional) 3.1.2 Least Squares (LS) Estimates
To obtain the LS estimates, we can either compute them using the algebraic formulas or fit the SLR model using the function lm( ). The lm( ) function follows the general form of goal( y ~ x , data ), where goal is replaced with lm. Note that lm stands for linear model.
To illustrate the first method, recall that the LS estimators of \(\beta_0\) and \(\beta_1\) are
\[
b_1=\frac{\sum (x_i-\bar{x})(y_i-\bar{y}) }{\sum (x_i-\bar{x})^2}, \quad ~~~~b_0=\bar{y}- b_1\bar{x}
\]
To apply these formulas, we use the function mean( ). This function follows the general form goal( ~ x , data) but goal becomes mean :
### extract 'xvar' and assign the values to `myx':
myx <- toluca.data$xvar
### same for yvar:
myy <- toluca.data$yvar
### Compute required differences.
### Note that we have no data argument
### since 'myx' was defined above and is
### not part of a dataframe.
XminusXbar <- myx - mean( ~ myx )
YminusYbar <- myy - mean( ~ myy )
XminusXbarSq <- XminusXbar^2 # squared differences
### Apply for LS formulas for LS estimates
b.1=sum( ( myx - mean( ~ myx) )*( myy - mean( ~ myy ) ) )/sum( ( myx-mean( ~ myx ) )^2 )
b.1
#> [1] 3.570202
b.0=mean( ~ myy ) - b.1*mean( ~ myx )
b.0
#> [1] 62.36586Thus, \(b_1=3.570\) and \(b_0=62.366\).
The lm( ) function follows the formula goal( y ~ x , data ). This function requires the name of the dataframe and the variables used in the dataframe. Recall that the variables in toluca.data are called yvar and xvar:
### fit the model
lm( yvar ~ xvar , data= toluca.data )
#>
#> Call:
#> lm(formula = yvar ~ xvar, data = toluca.data)
#>
#> Coefficients:
#> (Intercept) xvar
#> 62.37 3.57Although the lm( ) function only prints the LS estimates, it actually computes a lot of information that is only retrievable if we store the lm( ) result in an R object. Such objects are generally called lm objects. So, we store the result of lm( ) to an R object (I called it toluca.fit below) so that we can extract certain information as needed:
### fit the model and store the model fit
toluca.fit <- lm( yvar ~ xvar , data= toluca.data)To view the LS estimates, we summarize the lm object, toluca.fit, using the summary( ) function:
### summarize the fit <-- returns alot of info
summary( toluca.fit )
#>
#> Call:
#> lm(formula = yvar ~ xvar, data = toluca.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -83.876 -34.088 -5.982 38.826 103.528
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 62.366 26.177 2.382 0.0259 *
#> xvar 3.570 0.347 10.290 4.45e-10 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 48.82 on 23 degrees of freedom
#> Multiple R-squared: 0.8215, Adjusted R-squared: 0.8138
#> F-statistic: 105.9 on 1 and 23 DF, p-value: 4.449e-10From the summary( ) output, we see that \(b_0=62.366\) and \(b_1=3.570\). More on the output provided by summary( ) later.
Alternateivly, we can extract the LS estimates by applying the function coef() to the lm object:
### The only info required is the name
### your lm object.
coef( toluca.fit )
#> (Intercept) xvar
#> 62.365859 3.5702023.1.3 Plotting the estimated regression line
Once we have access to our data or we fit and save the simple linear regression model using lm( ), we can plot the data along with the estimated LS line. There are two approaches for plotting the LS line: xyplot( ) or plotModel( ).
3.1.3.1 Using xyplot( )
The function xyplot( ) is used the same way as before but with an additional argument of type= c( "p", "r" ):
### Plot the data and model fit.
### Note: "p" tells R we want to plot the points.
### "r" tells R we want to add the est. regression
### line to the plot
xyplot( yvar ~ xvar , data= toluca.data , type= c( "p", "r" ) )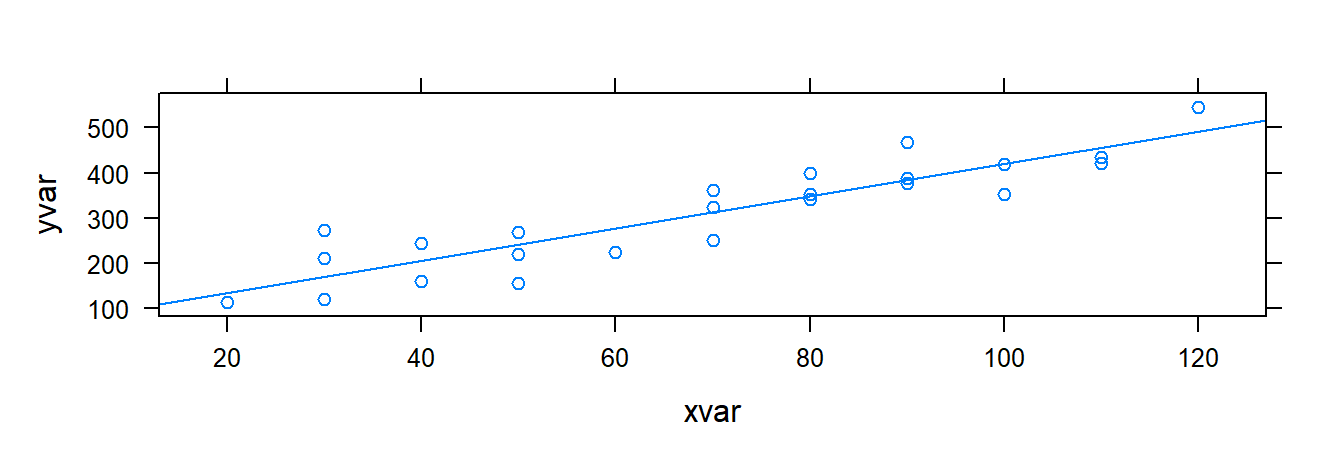
The argumenttype= c( "p", "r" ) tells R to plot the points and the estiamted regression line. Also recall that xyplot( ) has additional arguments to change axis label, add a title, etc.
3.1.3.2 Using plotModel( )
plotModel( ) will plot the data and the estimated LS line. It only has one argument, which will be an lm object:
### Plot the data and model fit.
plotModel( toluca.fit )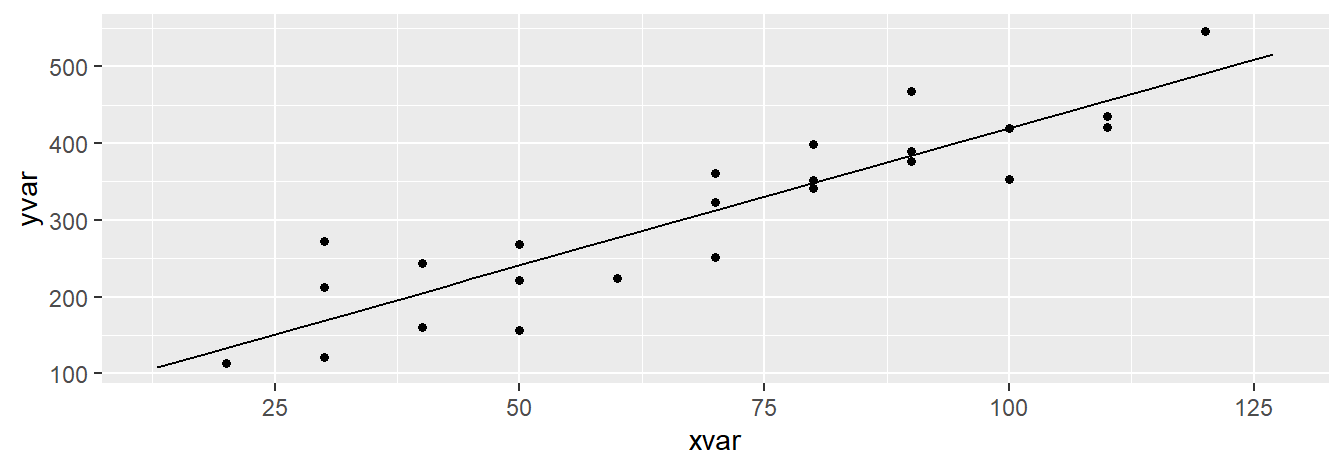
Which function should one use? They both provide the same info, but if you prefer to change some of the aesthetics of the plot, you will have to use xyplot( ) since, as of now, it is not possible to change the aesthetics of resulting plot provided by plotModel( ). For example:
xyplot( yvar ~ xvar , data = toluca.data , type= c( "p", "r" ), xlab = "Explanatory variable", ylab = "Response variable", main = "Estimated LS line", col = "green", pch = 3 )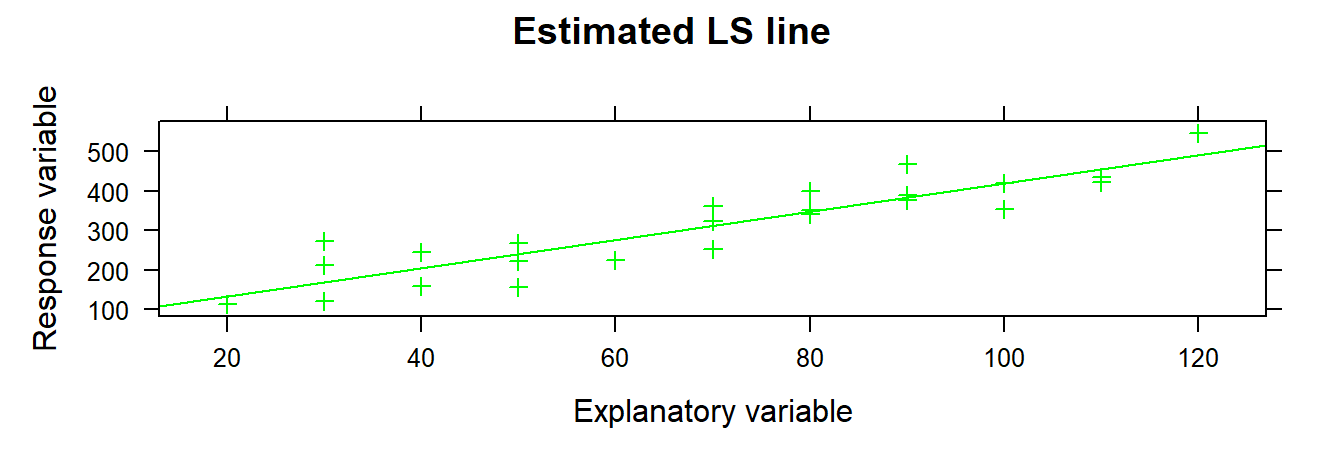
3.1.4 Fitted or predicted values
To obtain the fitted vales, \(\hat{y}_i=b_0+b_1 x_i\) for \(i=1,2,...,n\), we may use R by directly using the least square estimates obtained by using the summation formulas or more conveniently use the fitted.values( ) or predict( ) on an lm object:
### Only one argument: An lm object
fitted.values( toluca.fit )
#> 1 2 3 4 5 6 7 8
#> 347.9820 169.4719 240.8760 383.6840 312.2800 276.5780 490.7901 347.9820
#> 9 10 11 12 13 14 15 16
#> 419.3861 240.8760 205.1739 312.2800 383.6840 133.7699 455.0881 419.3861
#> 17 18 19 20 21 22 23 24
#> 169.4719 240.8760 383.6840 455.0881 169.4719 383.6840 205.1739 347.9820
#> 25
#> 312.2800
### predict( )
predict( toluca.fit )
#> 1 2 3 4 5 6 7 8
#> 347.9820 169.4719 240.8760 383.6840 312.2800 276.5780 490.7901 347.9820
#> 9 10 11 12 13 14 15 16
#> 419.3861 240.8760 205.1739 312.2800 383.6840 133.7699 455.0881 419.3861
#> 17 18 19 20 21 22 23 24
#> 169.4719 240.8760 383.6840 455.0881 169.4719 383.6840 205.1739 347.9820
#> 25
#> 312.2800Both fitted.values( ) or predict( ) can provided the fitted/predicted values for the observed values of \(x\). If instead you wanted to predict or fit values of \(y\) for certain levels or values of \(x\), we use predict( ) with an additional argument that corresponds to a dataframe that holds the x value(s) of interest. For example:
### This is a template on how to predict values of y
### for certain values of x.
### Suppose we wanted to predict the response when x=31 or x=119.
### First set up the dataframe that holds these values. Note that
### we have to use the name 'xvar' since this is the name of
### the predictor in toluca.data.
newdat <- data.frame( xvar=c(31, 119) ) # 'x' is the name of
# explanatory variable in the dataframe
### You have to specifiy an 'lm object'.
### newdata is a data frame holds the x values of interest.
predict( toluca.fit , newdata= newdat )
#> 1 2
#> 173.0421 487.21993.1.5 Residuals
The residuals are the differences between the observed values and the fitted values, denoted by \(e_i=y_i-\hat{y}_i\). The residuals can be obtained using the function residuals( ) whose only argument is an lm object:
### You have to specifiy an 'lm object'.
residuals( toluca.fit )
#> 1 2 3 4 5 6
#> 51.0179798 -48.4719192 -19.8759596 -7.6840404 48.7200000 -52.5779798
#> 7 8 9 10 11 12
#> 55.2098990 4.0179798 -66.3860606 -83.8759596 -45.1739394 -60.2800000
#> 13 14 15 16 17 18
#> 5.3159596 -20.7698990 -20.0880808 0.6139394 42.5280808 27.1240404
#> 19 20 21 22 23 24
#> -6.6840404 -34.0880808 103.5280808 84.3159596 38.8260606 -5.9820202
#> 25
#> 10.7200000
e <- residuals( toluca.fit ) # store them in a object called 'e'You may also compute them via:
### You have to specifiy an 'lm object'.
yhat <- fitted.values( toluca.fit )
toluca.data$yvar - yhat # observed - fitted/predicted
#> 1 2 3 4 5 6
#> 51.0179798 -48.4719192 -19.8759596 -7.6840404 48.7200000 -52.5779798
#> 7 8 9 10 11 12
#> 55.2098990 4.0179798 -66.3860606 -83.8759596 -45.1739394 -60.2800000
#> 13 14 15 16 17 18
#> 5.3159596 -20.7698990 -20.0880808 0.6139394 42.5280808 27.1240404
#> 19 20 21 22 23 24
#> -6.6840404 -34.0880808 103.5280808 84.3159596 38.8260606 -5.9820202
#> 25
#> 10.7200000
e <- toluca.data$yvar - yhat # store the result
3.1.6 summary( lm object ) output
So what is printed by summary( lm object )? The following output is given:
 The
The summary( ) output provides the LS estimates, the standard errors of the LS estimates, the test statistic for the regression line parameters, two-sided p-value to assess the significance of these parameters, the MSE, \(R^2\), and other information that we will revisit later.
3.1.7 Estimating of \(\sigma^2\)
To estimate the error variance component, one can either use the formula or use the summary( ) output. Using the formula we get:
### Recall we defined the residuals in a previous section
n <- 25 # from glimpse
sum( e^2 ) / ( n -2 )
#> [1] 2383.716The summary output provides \(\sqrt{MSE}\), which is an estimate of \(\sigma\). Based on the output, \(\hat{\sigma}^2=48.82^2 = 2383.392\)
3.2 Inference in simple linear regression
In this section, inference of the regression parameters using confidence intervals and hypothesis testing, inference about the mean response, prediction intervals for new observations, the ANOVA approach, and measures of association are addressed using R.
3.2.1 Inferences for \(\beta_0\) and \(\beta_1\)
The Toluca Company example from ALRM is used to illustrate inference on the slope and intercept of the model. Generally, inference is made about the slope of the model. A test and confidence interval concerning the intercept can be set up in the same manner as that of \(\beta_1\). To obtain the test statistic, along with p-values for test regarding those parameters, we summarize the lm object (the model fit) by using summary( ):
summary( toluca.fit)
#>
#> Call:
#> lm(formula = yvar ~ xvar, data = toluca.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -83.876 -34.088 -5.982 38.826 103.528
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 62.366 26.177 2.382 0.0259 *
#> xvar 3.570 0.347 10.290 4.45e-10 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 48.82 on 23 degrees of freedom
#> Multiple R-squared: 0.8215, Adjusted R-squared: 0.8138
#> F-statistic: 105.9 on 1 and 23 DF, p-value: 4.449e-10Recall that the summary( ) output provides the following:
Based on the output of summary( toluca.fit ), we obtain the estimates of \(\beta_1\) and \(\beta_0\) along with the test statistics \(b_1/s\{b_1\}\) and \(b_0/s\{b_0\}\) with the corresponding two-sided p-value for each.
Alternatively, we can also obtain the test statistic using the following commands:
MSE <- sum( e^2 )/( n-2 )
sd.b1 <-sqrt( MSE / ( sum( (X -mean( ~X ) )^2 ) ) )
t.star= b.1/sd.b1
t.star
#> [1] 0.2312414
# The test for the intercept is computed similarlyUnder \(H_0\), the distribution of the test statistic is \(t\) distribution with \(n-2\) (Notation: \(t_{n-2}\)). Recall that the p-value is the probability that the test statistic would take a value as extreme (or more extreme) as the observed test statistic in the the direction of the alternative if \(H_0\) were true.
If \(H_a: \beta >0\), the p-value = \(P( t_{n-2} > 10.290 )\). To obtain this probability we use the function xpt( q, df, lower.tail ). The value q will the value of interest (10.290 in this example), df corresponds to the degrees of freedom (n-2), and lower.tail will either be set equal to TRUE (computes the area to the left of q) or FALSE (computes the area to the right of q). To compute \(P( t_{n-2} > 10.290 )\), set lower.tail=FALSE:
xpt( q= 10.290, df= 25 - 2, lower.tail =FALSE)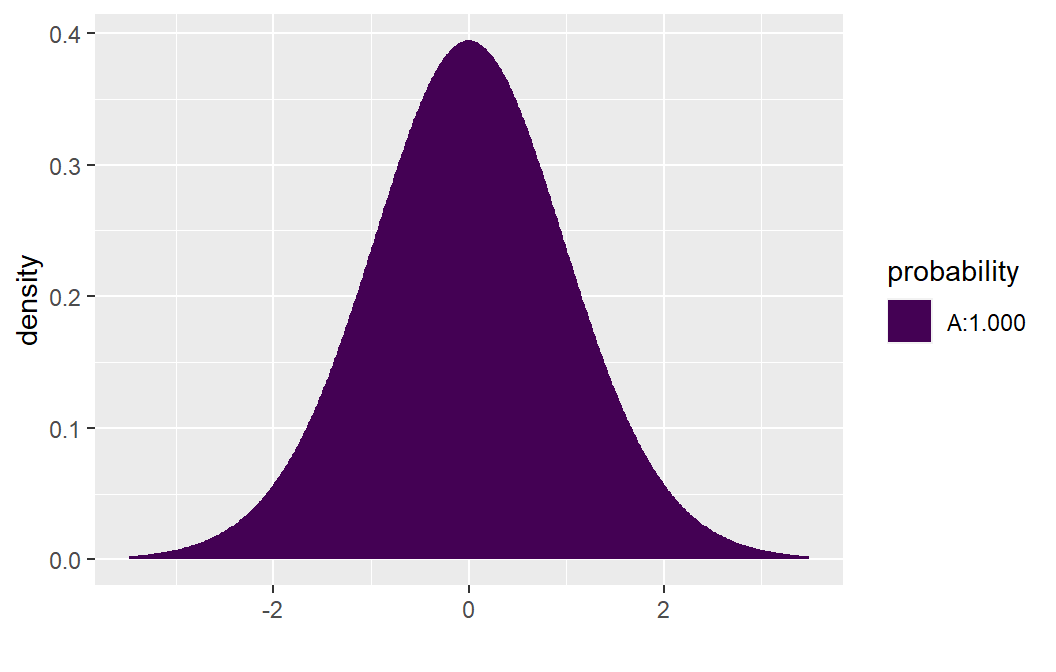
#> [1] 2.222735e-10The desired probability will be printed in the console: \(P( t_{n-2} > 10.290 ) \approx .0000000002\). This function will also produce a graph of the probability distribution with the area to the left of q shaded one color (area A) and the area to the right of q shaded another color (area B).
If instead \(H_a: \beta <0\), then set lower.tail=TRUE:
xpt( q= 10.290, df= 25 - 2, lower.tail =TRUE)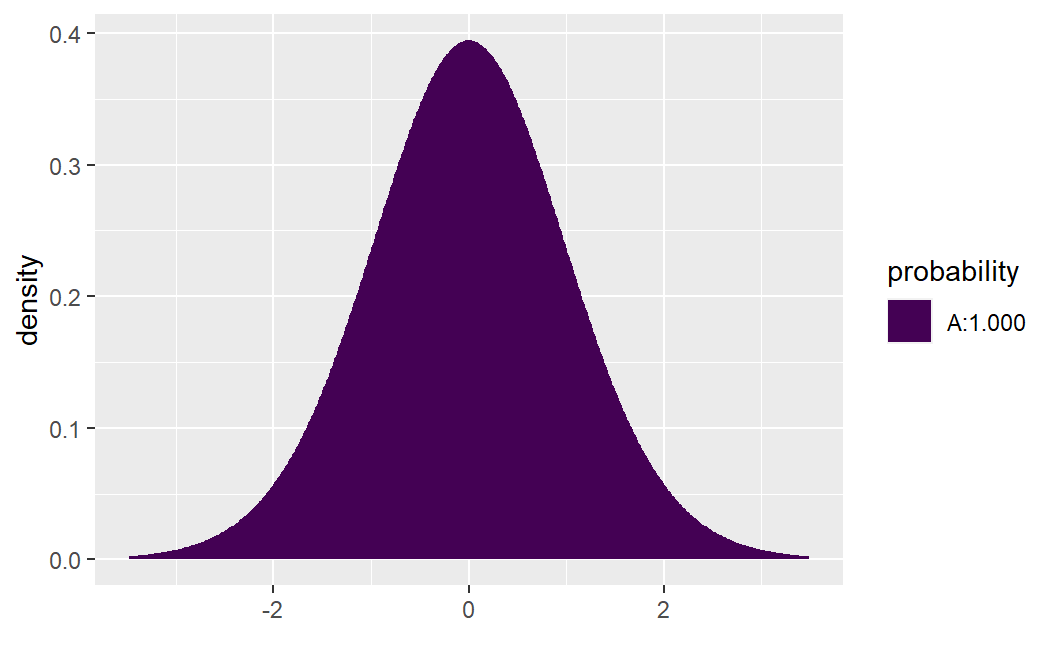
#> [1] 1The output shows that \(P( t_{n-2} < 10.290 ) \approx 1\). Lastly, if \(H_a: \beta \neq 0\), then we care about both possible extremes: \[P( t_{n-2} < -10.290 ) + P( t_{n-2} > 10.290 ) = 2 \times P( t_{n-2} > |10.290| )=.0000000004\]
For a confidence interval (CI) for \(\beta_1\), recall that the \(1-\alpha/2\) confidence limits for \(\beta_1\) are
\[b_1 \pm t_{1-\alpha/2, n-2} s\{b_1\}\]
To derive the CI, we can either use the summary( ) output along with the critical values provided by xqt( ), or you can use confint( ). Let’s first derive the CI using xqt( p, df, lower.tail ). This function provides the quantile for a specified probability. For the Toluca Company example suppose a 95% confidence interval is to be computed. Then, \(t_{1-.05/2,25-2}=\) xqt( 1-.05/2, df= 25-2)= 2.069.
xqt( 1-.05/2, df= 25-2)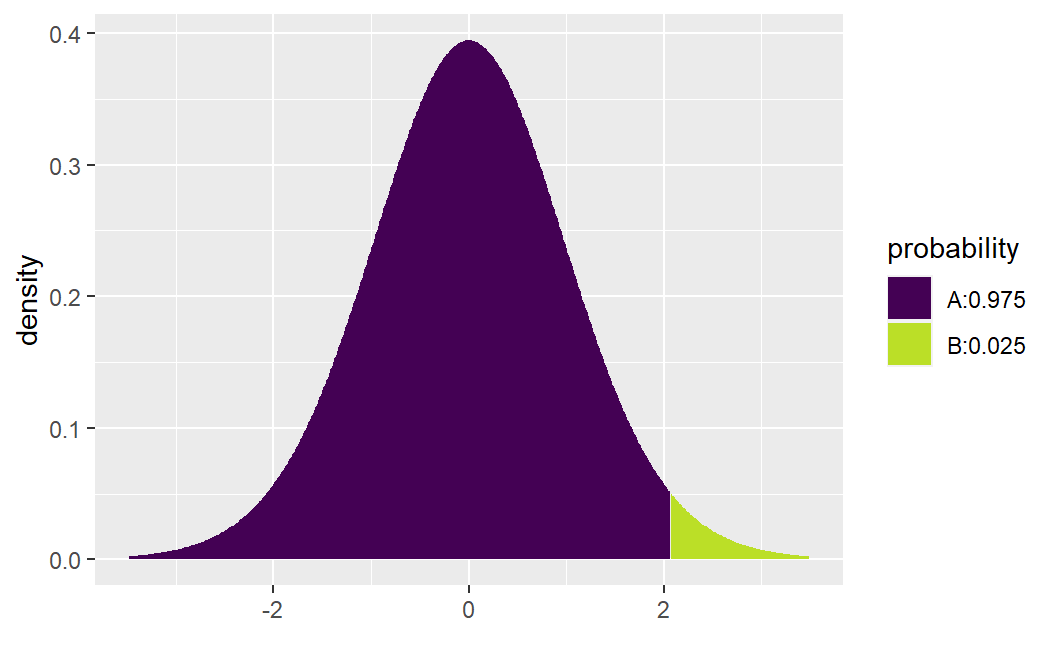
#> [1] 2.068658To obtain the CI, run the code below:
b1 <- 3.570 # from summary()
sb1 <- 0.347 # from summary()
b1 - 2.069*.347
#> [1] 2.852057
b1 + 2.069*.347
#> [1] 4.287943Since the model has been fitted, confint( ) will provide the CIs for both parameters. This function has two arguments: an lm object and the desired confidence level:
confint( toluca.fit, level = .95)
#> 2.5 % 97.5 %
#> (Intercept) 8.213711 116.518006
#> xvar 2.852435 4.2879693.2.2 CI for the mean response (\(E(y_h)\)) and a prediction interval for \(y_h\)
Following the Toluca Company example from ALRM, we obtain a CI for the point estimate \(y_h\) for \(x_h=100\) units by using the function predict( ). However, the function has two additional arguments, interval and level. We set interval=confidence and level to the desired confidence level:
X.new<- data.frame(xvar = c( 100 ) ) # xvar refers to the name of the variable
predict.lm( toluca.fit , newdata= X.new , interval = "confidence", level= .90 )
#> fit lwr upr
#> 1 419.3861 394.9251 443.847The prediction of a new observation and its corresponding prediction interval (PI) can be obtained in the same manner as the confidence interval for the mean response but we set interval= "prediciton":
### Note: X.new was defined above
predict.lm( toluca.fit , newdata= X.new , interval= "prediction", level= .90 )
#> fit lwr upr
#> 1 419.3861 332.2072 506.56493.2.3 Analysis of Variance approach to regression analysis
To obtain the ANOVA table in R, we use the function anova( lm object ):
anova(toluca.fit)
#> Analysis of Variance Table
#>
#> Response: yvar
#> Df Sum Sq Mean Sq F value Pr(>F)
#> xvar 1 252378 252378 105.88 4.449e-10 ***
#> Residuals 23 54825 2384
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The following output is given by anova( lm object ):

The output from anova( toluca.fit ) show that the p-value \(\approx\) 0. We could also use the function xpf( q , df1, df2, lower.tail ) to compute the p-value. The value q is the value of interest (105.88 in this example), df1 corresponds to the numerator degree of freedom (1), df2 corresponds to the denominator degree of freedom (25-2), and lower.tail would be set to FALSE since we want the p-value for this F-test:
xpf(q= 105.88, df1= 1, df2= 25-2 , lower.tail= FALSE)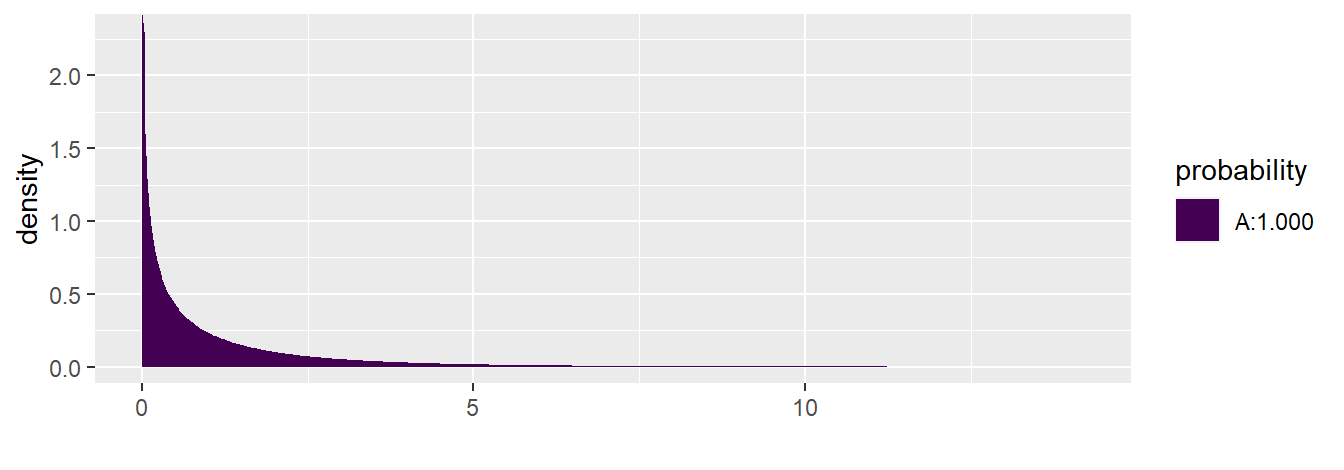
#> [1] 4.44711e-10Note that the shaded “A” area in the graph always corresponds to the area to the left of the value of interest. Area “B” does not appear since it is too small (\(\approx 0\))
3.2.4 Measures of association
The coefficient of determination (\(R^2\)) and coefficient of correlation (r) can be obtained from the SSR and SSTO (from the ANOVA table), by applying the summation formulas, or obtained from the summary( lm object ) output. The coefficient of or correlation is sign(\(b_1\))\((\sqrt{R^2})\). Using the summation formulas:
### extract the response and predictor
yresp <- toluca.data$yvar
xpred <- toluca.data$xvar
b.1 # recall the value of the slope est.
#> [1] 3.570202
SSR = b.1^2 * sum( ( xpred - mean( xpred ) )^2 )
SSTO = sum( ( yresp -mean( yresp ) )^2 )
R.sq = SSR/SSTO
R.sq
#> [1] 0.8215335
r=(1)*sqrt(R.sq) # slope est. is positiveNote that this matches the information provided in the output of summary discussed in a previous section.
3.3 Residual analysis and remedial measures
This section deals with assessing the appropriateness of the simple regression model. Residual analysis are performed on Toluca Company example from ALRM.
If we assume that \(\varepsilon_i \overset{iid}{\sim} N(0,\sigma^2)\) in the normal simple linear regression model, then the residuals \(e_i\)’s should reflect this property. We examine the assumption using the following residual plots:
| Things to examine | Residual plots to examine | |
| Normality | Normal QQ-plot of the residual | |
| Independence | residuals vs x or \(\hat{y}\) | |
| Constant variance | residuals vs x or \(\hat{y}\) | |
| Linearity | residuals vs x or \(\hat{y}\) | |
| Outliers | residuals vs x or \(\hat{y}\); QQ-plot of the residuals |
If we do not assume normality, the QQ-plot should still be examined for signs that the residuals show may be heavy-tailed distributed.
3.3.1 Creating residual plots
To create the plots to assess each of these assumptions, we use xyplot( ) and xqqmath( ). The following code creates the required plots:
### extract the fitted values from the lm object
tolucafitted <- fitted( toluca.fit )
### extract the residuals from the lm object
tolresids <- residuals( toluca.fit )
### Note: There is no time variable
### Residuals vs x
xyplot( tolresids ~ xvar, data=toluca.data, main= "Residuals vs x")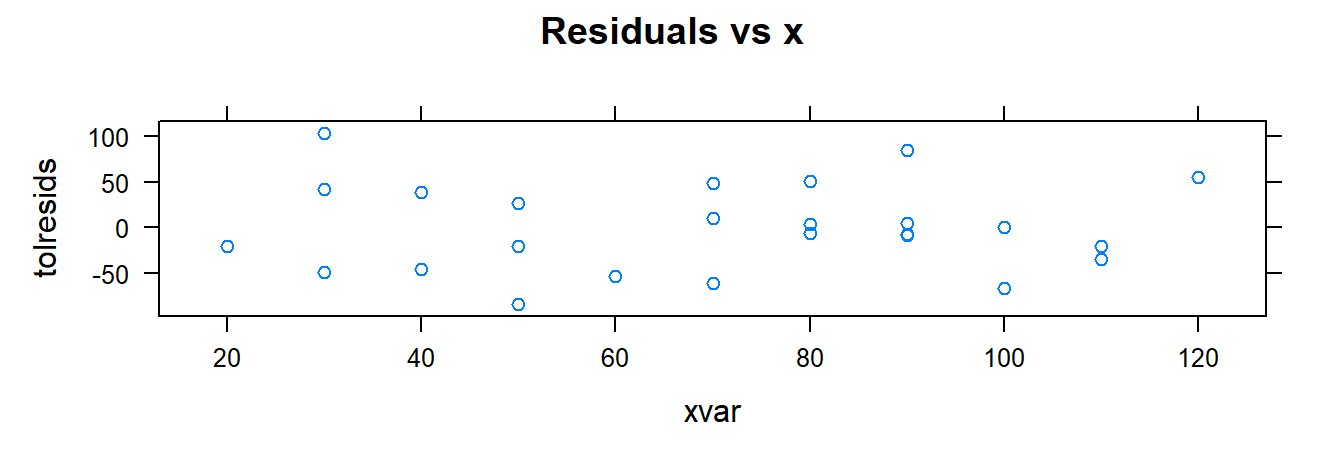
### Residuals vs fitted values
xyplot( tolresids ~ tolucafitted, data=toluca.data, main= "Residuals vs fitted")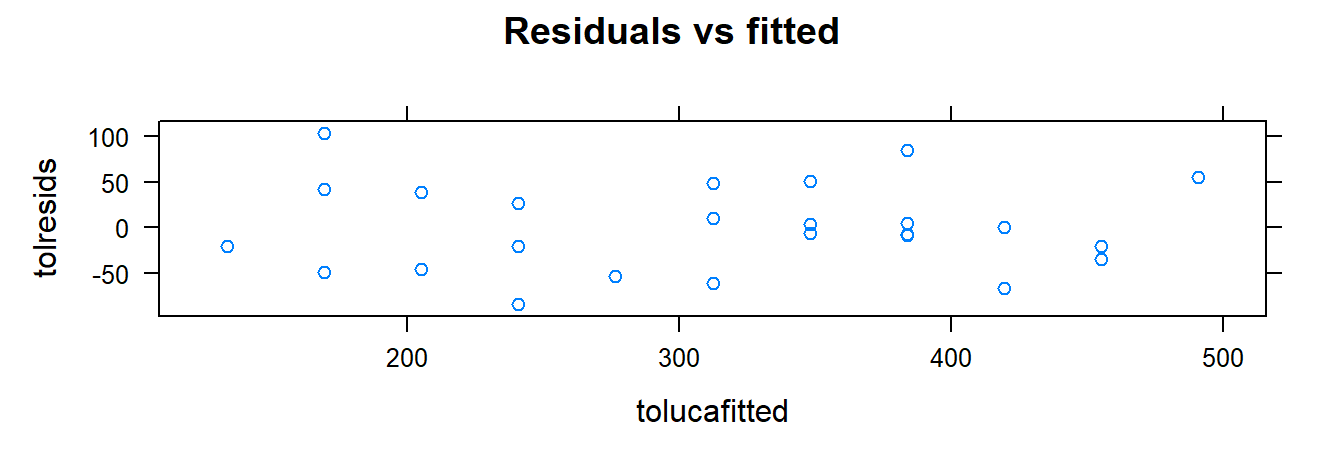
### QQ-plot of the residuals.
### xqqmath follows the general formula
### with an additional argument: goal( ~ x, data, distribution= "qnorm")
### There is no data argument since the residuals are
### already in R's memory since we created
### 'tolresids'.
xqqmath( ~ tolresids, distribution = "qnorm" )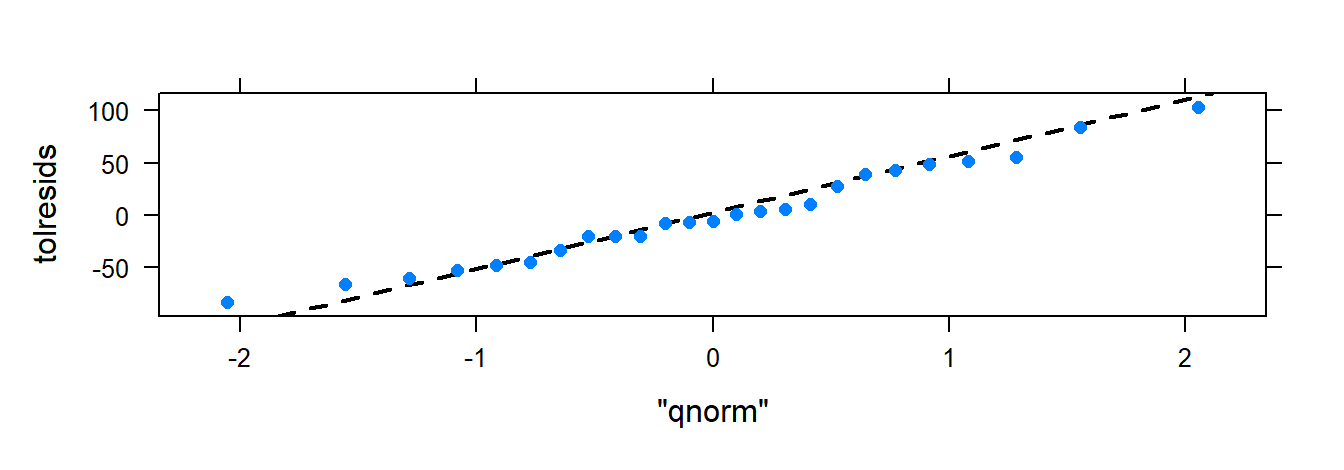
Although the above graphical summaries above are generally sufficient for diagnostics, one may examine other residual plots:
### boxplot of the residuals
gf_boxplot( ~ tolresids, main="Boxplot of residuals" ) 
### histogram of the residuals
histogram( ~ tolresids )
3.3.2 Testing departures from normality
R code is provided to carry out the Shapiro-Wilk and Lilliefors (Kolmogorov-Smirnov) test for normality. Both of these test may be used to detect if the residuals do not follow a normal distribution. The null hypothesis is that the residuals are normally distributed. The alternative is that they are not normally distributed. Thus, we are not testing if the residuals are normally distributed but rather if they depart from the normal distribution.
### Shapiro-Wilk Normality Test
shapiro.test( tolresids )
#>
#> Shapiro-Wilk normality test
#>
#> data: tolresids
#> W = 0.9789, p-value = 0.8626
### Lilliefors test of normality.
### First install the 'nortest' R package
require( "nortest" )
lillie.test( tolresids )
#>
#> Lilliefors (Kolmogorov-Smirnov) normality test
#>
#> data: tolresids
#> D = 0.09572, p-value = 0.8027For both tests, the p-value is much larger than a reasonable \(\alpha\) level.
3.3.3 Transformations
A possible remedial measure when the simple linear regression model is not appropriate is to transform the response and/or predictor variable. To transform a variable, we use the mutate( ) which comes from the dplyr package. The dplyr package is automatically installed when you install the mosaic package, and the dplyr package is automatically loaded when you load the mosaic package. The mutate( ) function requires the name of the dataframe and the name of a new variable/object that will hold your transformed variable:
mutate( ‘dataframe name’, ‘new variable’= ‘transformed variable’)
To illustrate transformation, we use the data from Toluca Company example. Specifically, we want to apply a square root transformation to the response variable and a natural log transformation to the explanatory variable:
### Recall toluca.data
glimpse( toluca.data )
#> Rows: 25
#> Columns: 2
#> $ xvar <int> 80, 30, 50, 90, 70, 60, 120, 80, 100, 50, 40, 70, 90, 20, 110, 10~
#> $ yvar <int> 399, 121, 221, 376, 361, 224, 546, 352, 353, 157, 160, 252, 389, ~
### Apply the square root trans. to the
### response. This function will add it to
### the dataframe
mutate( toluca.data, sqrty= sqrt( yvar ) ) # the squared root variable will be called sqrty
#> xvar yvar sqrty
#> 1 80 399 19.97498
#> 2 30 121 11.00000
#> 3 50 221 14.86607
#> 4 90 376 19.39072
#> 5 70 361 19.00000
#> 6 60 224 14.96663
#> 7 120 546 23.36664
#> 8 80 352 18.76166
#> 9 100 353 18.78829
#> 10 50 157 12.52996
#> 11 40 160 12.64911
#> 12 70 252 15.87451
#> 13 90 389 19.72308
#> 14 20 113 10.63015
#> 15 110 435 20.85665
#> 16 100 420 20.49390
#> 17 30 212 14.56022
#> 18 50 268 16.37071
#> 19 90 377 19.41649
#> 20 110 421 20.51828
#> 21 30 273 16.52271
#> 22 90 468 21.63331
#> 23 40 244 15.62050
#> 24 80 342 18.49324
#> 25 70 323 17.97220We want to be able to use the transformed variable, so we store the resulting new dataframe to a new object:
toluca.dataVer1 <- mutate( toluca.data, sqrty= sqrt( yvar ) )
glimpse( toluca.dataVer1 )
#> Rows: 25
#> Columns: 3
#> $ xvar <int> 80, 30, 50, 90, 70, 60, 120, 80, 100, 50, 40, 70, 90, 20, 110, 1~
#> $ yvar <int> 399, 121, 221, 376, 361, 224, 546, 352, 353, 157, 160, 252, 389,~
#> $ sqrty <dbl> 19.97498, 11.00000, 14.86607, 19.39072, 19.00000, 14.96663, 23.3~Now apply the natural log transformation to the explanatory variable:
### Apply natural log trans. to x.
### Note that we are using toluca.dataVer1
### dataframe since it already includes 'sqrty'.
toluca.dataVer2 <- mutate( toluca.dataVer1, lnx = log( xvar ) )
glimpse( toluca.dataVer2 )
#> Rows: 25
#> Columns: 4
#> $ xvar <int> 80, 30, 50, 90, 70, 60, 120, 80, 100, 50, 40, 70, 90, 20, 110, 1~
#> $ yvar <int> 399, 121, 221, 376, 361, 224, 546, 352, 353, 157, 160, 252, 389,~
#> $ sqrty <dbl> 19.97498, 11.00000, 14.86607, 19.39072, 19.00000, 14.96663, 23.3~
#> $ lnx <dbl> 4.382027, 3.401197, 3.912023, 4.499810, 4.248495, 4.094345, 4.78~
### One could also apply as many trans. as one would
### like by using mutate only once:
toluca.dataWithTrans <- mutate( toluca.data, sqrty= sqrt( yvar ), lnx = log( xvar ),
lny = log( yvar ) , sqrd = yvar^2, cubertx = xvar^( 1/3 ) )
glimpse( toluca.dataWithTrans )
#> Rows: 25
#> Columns: 7
#> $ xvar <int> 80, 30, 50, 90, 70, 60, 120, 80, 100, 50, 40, 70, 90, 20, 110,~
#> $ yvar <int> 399, 121, 221, 376, 361, 224, 546, 352, 353, 157, 160, 252, 38~
#> $ sqrty <dbl> 19.97498, 11.00000, 14.86607, 19.39072, 19.00000, 14.96663, 23~
#> $ lnx <dbl> 4.382027, 3.401197, 3.912023, 4.499810, 4.248495, 4.094345, 4.~
#> $ lny <dbl> 5.988961, 4.795791, 5.398163, 5.929589, 5.888878, 5.411646, 6.~
#> $ sqrd <dbl> 159201, 14641, 48841, 141376, 130321, 50176, 298116, 123904, 1~
#> $ cubertx <dbl> 4.308869, 3.107233, 3.684031, 4.481405, 4.121285, 3.914868, 4.~Once the transformed variables are stored in a dataframe, you can plot them or fit the simple linear regression model:
# Note the dataframe name
xyplot(sqrty ~ xvar, data= toluca.dataWithTrans, main="Square root of y vs x" )
xyplot(sqrty ~ lnx, data= toluca.dataWithTrans, main="Square root of y vs ln(x)" )
toluca.fitA <- lm( sqrty ~ xvar , data= toluca.dataWithTrans )
toluca.fitA
#>
#> Call:
#> lm(formula = sqrty ~ xvar, data = toluca.dataWithTrans)
#>
#> Coefficients:
#> (Intercept) xvar
#> 9.9722 0.10553.3.4 F Test for Lack of Fit
Th lack of fit test requires repeated observations at one or more \(x\) levels. To proceed, one may compute the MSLF and MSPE using the summation formulas using R. An easier approach is determine the full and reduced model when testing for a lack of fit. Recall that in this setting we have the following models:
Full Model: \(Y_{ij}=\mu_j + \varepsilon_{ij}\)
Reduced Model: \(Y_{ij}= \beta_0 + \beta_1 X_j +\varepsilon_{ij}\)
If the full and reduced model can be determined (and are nested), then one may use the general F-test to test whether we can reject the null hypothesis (which postulates the reduced model). In R, the general F-test can be carried out using anova( reduced model , full model , test= "F" ) . Note that in this case, the reduced model is a single-factor (potentially) unbalanced AOV model. We follow the Bank Example from ALRM to illustrate this in R:
### Import data:
url <- "http://www.csub.edu/~emontoya2/datasets/textbookdata/Kutner/Chapter%20%203%20Data%20Sets/CH03TA04.txt"
bank.data <- read.csv( url , header = FALSE , col.names = c("x", "y") , sep = "" )
glimpse( bank.data )
#> Rows: 11
#> Columns: 2
#> $ x <int> 125, 100, 200, 75, 150, 175, 75, 175, 125, 200, 100
#> $ y <int> 160, 112, 124, 28, 152, 156, 42, 124, 150, 104, 136
### Fit full model, but first convert
### the explanatory into a factor variable.
### 'as.factor" converts a variable into a factor variable.
bank.dataUD <- mutate( bank.data, xfac = as.factor( x ) )
# 'levels' counts how many levels are present in a
# factor variable.
levels.x <- levels( bank.dataUD$xfac ) # determine the levels of X
levels.x
#> [1] "75" "100" "125" "150" "175" "200"
n <- 11 # from glimpse( )
c <- 6 # how many levels
c
#> [1] 6
n - c
#> [1] 5
### Full model:
### (Note: for those that have taken 4220: this is a one-way unbalanced aov problem)
fit.bank.full <- lm(y~ xfac , data= bank.dataUD)
### Reduced model:
fit.bank.reduced <- lm(y~ x , data= bank.dataUD)
### anova(reduced model, full model, test="F")
anova( fit.bank.reduced , fit.bank.full , test= "F" )
#> Analysis of Variance Table
#>
#> Model 1: y ~ x
#> Model 2: y ~ xfac
#> Res.Df RSS Df Sum of Sq F Pr(>F)
#> 1 9 14742
#> 2 5 1148 4 13594 14.801 0.005594 **
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1What information is given by anova( fit.bank.reduced , fit.bank.full , test="F")? We obtain

3.4 Least absolute deviation (LAD) regression
The method of least squares minimizes the distances between the observed data points and the corresponding points on the fitted regression line. Least squares estimates for linear regression assume all model assumptions are valid. When some of these assumptions are invalid, least squares regression can perform poorly for inference. Robust or resistant regression methods provide an alternative to least squares estimation by attempting to dampen the influence of outliers in order to provide a better fit of the model to the data. On such method is LAD regression
Residual diagnostics can help guide you to where the breakdown in assumptions occur, but can be time consuming and sometimes difficult to the untrained eye. Robust regression methods provide an alternative to least squares regression by requiring less restrictive assumptions. These methods attempt to dampen the influence of outlying cases in order to provide a better fit to the majority of the data.
3.5 The matrix approach to simple linear regression
3.5.1 Creating a matrix
Recall that the function c( ) creates a vector. For example,
xvec <- c( 4, 5, 6, 7 )We can select a given element from this vector by placing [ ] after the vector name with a specified index:
### 1st element in the vector
xvec[1]
#> [1] 4
xvec[3] # 3rd element in the vector
#> [1] 6A matrix is a rectangular way of storing data. You can think of it as simply a way to store data. Matrices will have two dimensions: rows and columns. That is, each matrix will consist of rows and columns of elements (or data).
The function matrix( ) allows a user to create a matrix from a vector of data. The function has four arguments: data (a vector of data), nrow (desired number of rows), ncol (desired number of columns), and byrow (set equal to FALSE if the matrix is to be filled by column, set to TRUE if to be filled by row). The code below create a vector of data to be transformed into a matrix:
3.5.2 Some matrix operations
It may be necessary to perform certain matrix operations. In this section you will learn how to perform matrix multiplication, transpose a matrix, obtain the inverse of a matrix, and element by element multiplication. The commands that we will use are:
| Name | What does it do? | |
| %*% | Performs matrix multiplication | |
| t( ) | Transposes a matrix. | |
| solve( ) | Obtains an Inverse of a matrix | |
| * | Performs element by element multiplication. |
The commands are illustrated with the following code:
### Create two matrices
C= matrix( c( 1, 2, 1, -8, 26, 4, 5, 6, 10 ) , nrow= 3, ncol= 3 )
D= matrix( c( 7, 8, 9, 10, 11, 12, 13, 14, 15 ), nrow= 3, ncol= 3 )
C
#> [,1] [,2] [,3]
#> [1,] 1 -8 5
#> [2,] 2 26 6
#> [3,] 1 4 10
D
#> [,1] [,2] [,3]
#> [1,] 7 10 13
#> [2,] 8 11 14
#> [3,] 9 12 15
### Matrix multiplication
C%*%D # multiply matrices A and B
#> [,1] [,2] [,3]
#> [1,] -12 -18 -24
#> [2,] 276 378 480
#> [3,] 129 174 219
### Matrix transpose
t(C) # transpose of matrix A
#> [,1] [,2] [,3]
#> [1,] 1 2 1
#> [2,] -8 26 4
#> [3,] 5 6 10
### element by element multiplication
C*D # this is NOT matrix multiplication
#> [,1] [,2] [,3]
#> [1,] 7 -80 65
#> [2,] 16 286 84
#> [3,] 9 48 150
### obtain the inverse of A
solve(C)
#> [,1] [,2] [,3]
#> [1,] 0.91472868 0.38759690 -0.68992248
#> [2,] -0.05426357 0.01937984 0.01550388
#> [3,] -0.06976744 -0.04651163 0.16279070
### Add two matrices
C + D
#> [,1] [,2] [,3]
#> [1,] 8 2 18
#> [2,] 10 37 20
#> [3,] 10 16 253.5.3 LS estimation
The simple linear regression model in matrix form is
\[ \boldsymbol{Y}_{n\times1} = \boldsymbol{X}_{n\times 2} \boldsymbol{\beta}_{2\times1} + \boldsymbol{\varepsilon}_{n\times1} \]
where
\[ \boldsymbol{Y}_{n\times 1}= \begin{bmatrix} y_{1} \\ y_{2} \\ \vdots \\ y_{n} \\ \end{bmatrix}, \qquad \boldsymbol{X}_{n\times 2}= \begin{bmatrix} 1 & x_{1} \\ 1 & x_{2} \\ \vdots \\ 1 & x_{n} \\ \end{bmatrix}, \qquad \boldsymbol{\beta}_{2\times 1}= \begin{bmatrix} \beta_{0} \\ \beta_{1} \\ \end{bmatrix}, \quad and \quad \boldsymbol{\varepsilon}_{n\times 1}= \begin{bmatrix} \varepsilon_{1} \\ \varepsilon_{2} \\ \vdots \\ \varepsilon_n\\ \end{bmatrix} \]
The matrix approach is illustrated in R using the Toluca Company example:
### Recall the data
glimpse( toluca.data )
#> Rows: 25
#> Columns: 2
#> $ xvar <int> 80, 30, 50, 90, 70, 60, 120, 80, 100, 50, 40, 70, 90, 20, 110, 10~
#> $ yvar <int> 399, 121, 221, 376, 361, 224, 546, 352, 353, 157, 160, 252, 389, ~
### Extract both variables to set up the matrices
hrs <- toluca.data$yvar
lotsize <- toluca.data$xvar
### Set up the response column vector
yvec <- matrix( hrs, nrow= 25, ncol= 1)
yvec
#> [,1]
#> [1,] 399
#> [2,] 121
#> [3,] 221
#> [4,] 376
#> [5,] 361
#> [6,] 224
#> [7,] 546
#> [8,] 352
#> [9,] 353
#> [10,] 157
#> [11,] 160
#> [12,] 252
#> [13,] 389
#> [14,] 113
#> [15,] 435
#> [16,] 420
#> [17,] 212
#> [18,] 268
#> [19,] 377
#> [20,] 421
#> [21,] 273
#> [22,] 468
#> [23,] 244
#> [24,] 342
#> [25,] 323
### Define the design/model matrix.
# First we need to define a vectors of 1's:
ones <- rep( 1, times= 25)
ones
#> [1] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
# If you have the columns of the matrix
# already defined, then we can create the
# matrix by binding the columns using 'cbind()'.
Xmat <- cbind( ones , lotsize )
Xmat
#> ones lotsize
#> [1,] 1 80
#> [2,] 1 30
#> [3,] 1 50
#> [4,] 1 90
#> [5,] 1 70
#> [6,] 1 60
#> [7,] 1 120
#> [8,] 1 80
#> [9,] 1 100
#> [10,] 1 50
#> [11,] 1 40
#> [12,] 1 70
#> [13,] 1 90
#> [14,] 1 20
#> [15,] 1 110
#> [16,] 1 100
#> [17,] 1 30
#> [18,] 1 50
#> [19,] 1 90
#> [20,] 1 110
#> [21,] 1 30
#> [22,] 1 90
#> [23,] 1 40
#> [24,] 1 80
#> [25,] 1 70The LS estimates may be obtained via \(\boldsymbol{b}= ( \boldsymbol{X}^T\boldsymbol{X})^{-1}\boldsymbol{X}^{T} \boldsymbol{y}\). In R we have:
XmatTxmat <- t(Xmat) %*% Xmat
solve( XmatTxmat ) %*% t(Xmat) %*% yvec
#> [,1]
#> ones 62.365859
#> lotsize 3.570202These are the same estimates provided by summary( ).
The fitted values, \(\boldsymbol{\hat{y}} = \boldsymbol{X} \boldsymbol{b}\), are obtained via:
### Store the LS estimates
best <- solve( XmatTxmat ) %*% t(Xmat) %*% yvec
Xmat %*% best # compare to fitted(toluca.fit)
#> [,1]
#> [1,] 347.9820
#> [2,] 169.4719
#> [3,] 240.8760
#> [4,] 383.6840
#> [5,] 312.2800
#> [6,] 276.5780
#> [7,] 490.7901
#> [8,] 347.9820
#> [9,] 419.3861
#> [10,] 240.8760
#> [11,] 205.1739
#> [12,] 312.2800
#> [13,] 383.6840
#> [14,] 133.7699
#> [15,] 455.0881
#> [16,] 419.3861
#> [17,] 169.4719
#> [18,] 240.8760
#> [19,] 383.6840
#> [20,] 455.0881
#> [21,] 169.4719
#> [22,] 383.6840
#> [23,] 205.1739
#> [24,] 347.9820
#> [25,] 312.2800These values may also be obtained by using the hat matrix:
### Hat matrix
Hatmat <- Xmat %*% solve( XmatTxmat ) %*% t(Xmat)
Hatmat %*% yvec # same as above
#> [,1]
#> [1,] 347.9820
#> [2,] 169.4719
#> [3,] 240.8760
#> [4,] 383.6840
#> [5,] 312.2800
#> [6,] 276.5780
#> [7,] 490.7901
#> [8,] 347.9820
#> [9,] 419.3861
#> [10,] 240.8760
#> [11,] 205.1739
#> [12,] 312.2800
#> [13,] 383.6840
#> [14,] 133.7699
#> [15,] 455.0881
#> [16,] 419.3861
#> [17,] 169.4719
#> [18,] 240.8760
#> [19,] 383.6840
#> [20,] 455.0881
#> [21,] 169.4719
#> [22,] 383.6840
#> [23,] 205.1739
#> [24,] 347.9820
#> [25,] 312.28003.6 Multiple linear regression (MLR)
This section deals with the multiple regression model
\[ Y_i=\beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots +
\beta_p x_{i,p-1} + \varepsilon_i\]
where the \(\beta\)’s are the parameters, \(x\)’s are known constants, and we assume that \(\varepsilon_i \overset{iid}{\sim} N(0, \sigma^2)\). To illustrate the model fitting with R we follow the Dwaine Studios Example from ALRM. Note that the model can be expressed in matrix form and any subsequent analyses can be done in terms of matrices. Matrices will be used to obtain the least square estimates as an illustration of using matrices R, but the rest of the analyses will be done using lm( ) and anova( ).
3.6.1 Least-Squares Estimates
Begin by importing the data:
### Import data:
url <- "http://www.csub.edu/~emontoya2/datasets/textbookdata/Kutner/Chapter%20%206%20Data%20Sets/CH06FI05.txt"
dwaine.data <- read.csv( url , header = FALSE , col.names = c("x1", "x2", "y") , sep = "" )
glimpse( dwaine.data )
#> Rows: 21
#> Columns: 3
#> $ x1 <dbl> 68.5, 45.2, 91.3, 47.8, 46.9, 66.1, 49.5, 52.0, 48.9, 38.4, 87.9, 7~
#> $ x2 <dbl> 16.7, 16.8, 18.2, 16.3, 17.3, 18.2, 15.9, 17.2, 16.6, 16.0, 18.3, 1~
#> $ y <dbl> 174.4, 164.4, 244.2, 154.6, 181.6, 207.5, 152.8, 163.2, 145.4, 137.~A matrix approach can be used as follows:
n <- 21
yresp <- dwaine.data$y
Xmat <- cbind(rep(1, n), dwaine.data$x1, dwaine.data$x2) # design/model matrix
yrespvec <- matrix( yresp, ncol = 1, nrow=21)
b <- solve( t( Xmat )%*%( Xmat ) )%*%t( Xmat )%*%yrespvec
b
#> [,1]
#> [1,] -68.85707
#> [2,] 1.45456
#> [3,] 9.36550We can also lm( ) to fit a MLR model. It is used in the same manner as before but we add additional explanatory variables by adding a + after each explanatory variable:
### Note the argument of lm():
### Response variable ∼ Explanatory variable + Explanatory variable + ...
dwaine.fit <- lm( y ~ x1 + x2 , data= dwaine.data)
dwaine.fit
#>
#> Call:
#> lm(formula = y ~ x1 + x2, data = dwaine.data)
#>
#> Coefficients:
#> (Intercept) x1 x2
#> -68.857 1.455 9.3663.6.2 Fitted values, ANOVA table, residuals
All previously discussed functions that extract information from an lm obejct such as the LS estimates, fitted values, ANOVA table, etc. can be use in the same manner when fitting a MLR model. Recall that coef( ) returns the LS estimates:
coef(dwaine.fit)
#> (Intercept) x1 x2
#> -68.85707 1.45456 9.36550The fitted values and residuals can be obtained via:
fitted(dwaine.fit)
#> 1 2 3 4 5 6 7 8
#> 187.1841 154.2294 234.3963 153.3285 161.3849 197.7414 152.0551 167.8666
#> 9 10 11 12 13 14 15 16
#> 157.7382 136.8460 230.3874 197.1849 222.6857 141.5184 174.2132 228.1239
#> 17 18 19 20 21
#> 145.7470 159.0013 230.9870 230.3161 157.0644
residuals( dwaine.fit )
#> 1 2 3 4 5 6
#> -12.7841146 10.1705737 9.8036764 1.2714690 20.2150722 9.7585779
#> 7 8 9 10 11 12
#> 0.7449178 -4.6666316 -12.3381967 0.3539791 11.5126289 -6.0849209
#> 13 14 15 16 17 18
#> 9.3142995 3.7815611 -13.1132116 -18.4238900 0.6530062 -15.0013134
#> 19 20 21
#> 1.6129777 -6.2160615 9.4356009To obtain the ANOVA table, run the following:
anova( dwaine.fit )
#> Analysis of Variance Table
#>
#> Response: y
#> Df Sum Sq Mean Sq F value Pr(>F)
#> x1 1 23371.8 23371.8 192.8962 4.64e-11 ***
#> x2 1 643.5 643.5 5.3108 0.03332 *
#> Residuals 18 2180.9 121.2
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1What information is given by anova( dwaine.fit )? We obtain
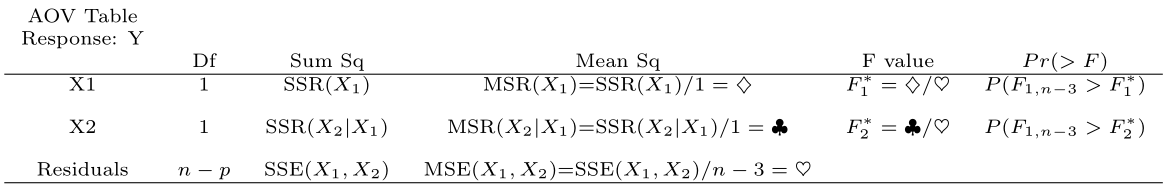
The ANOVA table returned by R gives the decomposition of \(SSR(X_1, X_2)\) (Chapter 7 material). Note that \(SSR(X_1,X_2)=SSR(X_1)+SSR(X_2|X_1)\).
3.6.3 Inference about the regression parameters
To determine the significance of the regression parameter(s) we can summarized the fit:
summary( dwaine.fit )
#>
#> Call:
#> lm(formula = y ~ x1 + x2, data = dwaine.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -18.4239 -6.2161 0.7449 9.4356 20.2151
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) -68.8571 60.0170 -1.147 0.2663
#> x1 1.4546 0.2118 6.868 2e-06 ***
#> x2 9.3655 4.0640 2.305 0.0333 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 11.01 on 18 degrees of freedom
#> Multiple R-squared: 0.9167, Adjusted R-squared: 0.9075
#> F-statistic: 99.1 on 2 and 18 DF, p-value: 1.921e-10Note that the following is printed by summary(dwaine.fit):

Note that we are provided with the test statistic \(F^*\) to test whether sales are related to target population and per capita disposable income (\(\beta_1=0\) and \(\beta_2=0\)), and we are provided with the test statistic \(t^*\) for each regression parameter.
3.6.4 Inference about the Mean Response and Prediction of New Observation
As before, we can use predict( ) to obtain a CI for the mean response and a PI for a predicted response. For example, a 95% confidence interval for \(E(y_h)\) (expected sales in cities) in a community with \(x_{h1}=65.4\) (number of persons aged 16 or younger) and \(x_{h2}=17.6\) (per capita disposable personal income) is obtained in R by:
new.x.data <- data.frame(x1=65.4, x2=17.6)
predict(dwaine.fit, newdata=new.x.data, interval="confidence", level=.95)
#> fit lwr upr
#> 1 191.1039 185.2911 196.9168A 95% PI at these same levels of x1 and x2 is:
predict(dwaine.fit, newdata=new.x.data, interval="prediction", level=.95)
#> fit lwr upr
#> 1 191.1039 167.2589 214.949To predict at two difference communities in which in one community the number of persons aged 16 or younger is 65.4 and the per capita disposable personal income is 17.6, and the other has the number of persons aged 16 or younger is 53.1 and the per capita disposable personal income is 17.7 we enter the following:
new.x.data2 <- data.frame(x1=c(65.4, 53.1), x2=c(17.6, 17.7))
predict.lm(dwaine.fit, newdata=new.x.data2, interval="prediction", level=.95)
#> fit lwr upr
#> 1 191.1039 167.2589 214.9490
#> 2 174.1494 149.0867 199.21213.6.5 Diagnostics
Diagnostics are conducted in the same manner (QQ-plot of the residuals, scatterplots of the residuals versus \(\hat{y}\), scatterplots of the residuals versus \(\hat{y}\) versus a given \(x\)) as when the simple linear regression model was discussed, but now we also consider the scatter plot matrix and correlation matrix. The argument for both of these functions will be a dataframe.
splom( dwaine.data) # scatterplot matrix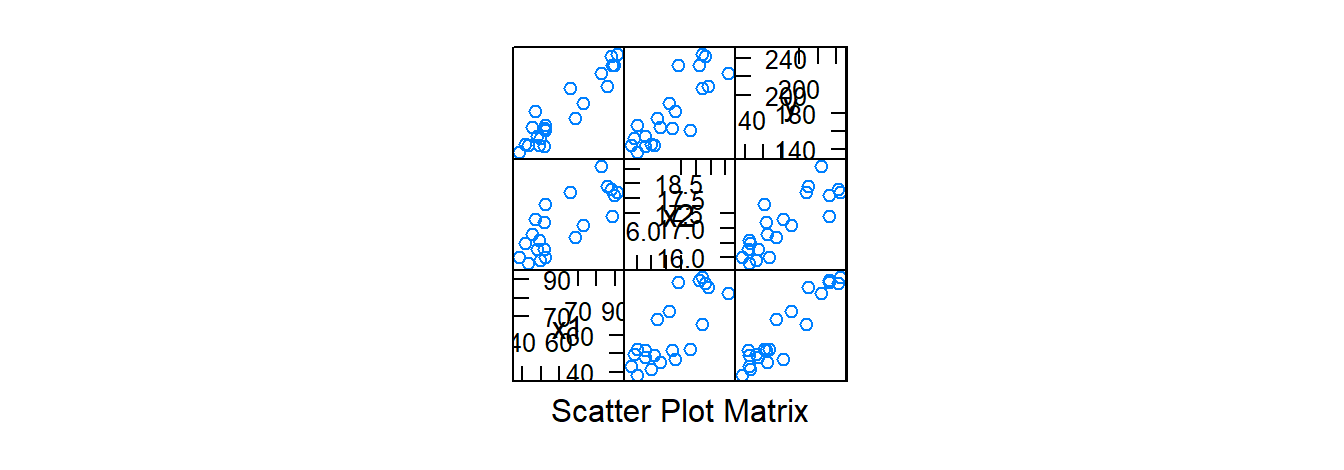
cor( dwaine.data ) # correlation matrix
#> x1 x2 y
#> x1 1.0000000 0.7812993 0.9445543
#> x2 0.7812993 1.0000000 0.8358025
#> y 0.9445543 0.8358025 1.00000003.6.6 ANOVA table containing decomposition of SSR
Here R is used to obtain an anova table with a decomposition of the SSR. We follow the Body Fat example from ALRM using R to obtain the anova table with the decomposition of SSR. The anova( ) function will automatically decompose the SSR with the
decomposition depending on the order that you enter the predictor
variables into lm( ). For example, to get the decomposition
\[SSR(x_1, x_2, x_3)=SSR(x_3)+SSR(x_2|x_3)+SSR(x_1|x_3, x_2)\]
we enter the predictors into lm() as y\(\thicksim\)x3 + x2 + x1.
### Import data:
url <- "https://www.csub.edu/~emontoya2/datasets/textbookdata/Kutner/Chapter%20%207%20Data%20Sets/CH07TA01.txt"
### This is not a .csv file and the file does not
### include variable names, so some changes
### have to be made to read.csv().
bf.data <- read.csv( url , header = FALSE , col.names = c( "x1", "x2", "x3", "y" ) , sep = "" )
glimpse( bf.data )
#> Rows: 20
#> Columns: 4
#> $ x1 <dbl> 19.5, 24.7, 30.7, 29.8, 19.1, 25.6, 31.4, 27.9, 22.1, 25.5, 31.1, 3~
#> $ x2 <dbl> 43.1, 49.8, 51.9, 54.3, 42.2, 53.9, 58.5, 52.1, 49.9, 53.5, 56.6, 5~
#> $ x3 <dbl> 29.1, 28.2, 37.0, 31.1, 30.9, 23.7, 27.6, 30.6, 23.2, 24.8, 30.0, 2~
#> $ y <dbl> 11.9, 22.8, 18.7, 20.1, 12.9, 21.7, 27.1, 25.4, 21.3, 19.3, 25.4, 2~
bf.fit=lm(y~ x3 + x2 + x1, data=bf.data)
anova(bf.fit)
#> Analysis of Variance Table
#>
#> Response: y
#> Df Sum Sq Mean Sq F value Pr(>F)
#> x3 1 10.05 10.05 1.6343 0.2193
#> x2 1 374.23 374.23 60.8471 7.684e-07 ***
#> x1 1 12.70 12.70 2.0657 0.1699
#> Residuals 16 98.40 6.15
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1One could also use the extra sums of squares formulas to get the decomposition desired.
3.6.7 Testing whether \(\beta_k \neq 0\) for some \(k\)
There are several ways to go about testing whether a single or multiple regression coefficients are significant using R. For example, we could get the appropriate extra sums of squares for the reduced model and the full model to calculate the appropriate test statistic. If the reduced model is nested under the full model then we can use anova( ) to compute the test statistic and corresponding p-value. All that is required is to specify the full model and the model under the null hypothesis (reduced model).
Suppose it is of interest to test the following hypothesis for the Body Fat example from ALRM:
\[ H_0: \beta_2=\beta_3=0\]
The reduced model is \(Y_i=\beta_0+\beta_1 X_{i1} + \varepsilon_i\)
and the full models is \(y_i=\beta_0+\beta_1 x_{i1} + \beta_2 x_{i2} +\beta_3 x_{i3}+ \varepsilon_i\). Clearly the models are
nested therefore we use the function anova( ):
reduced.fit <- lm( y ~ x1 , data= bf.data )
full.fit=lm( y ~ x1 + x2 + x3 , data=bf.data)
anova( reduced.fit , full.fit , test= "F" )
#> Analysis of Variance Table
#>
#> Model 1: y ~ x1
#> Model 2: y ~ x1 + x2 + x3
#> Res.Df RSS Df Sum of Sq F Pr(>F)
#> 1 18 143.120
#> 2 16 98.405 2 44.715 3.6352 0.04995 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The following is printed by anova( reduced.fit , full.fit,test='F' ):

3.7 Interactions
Suppose we wish to include the interaction of \(x_1 \times x_2\) in
One way to include an interaction term
is by specifying x1*x2 in the model formula.
Specifying x1*x2 instead of x1+x2 will include the
main effects and the interaction effect. An alternative way is to use mutate() to add a new
the predictor variable x1*x2. Both
methods are illustrated:
BodyFat.Inter=lm(y~ x1*x2 + x3, data=bf.data)
summary(BodyFat.Inter)
#>
#> Call:
#> lm(formula = y ~ x1 * x2 + x3, data = bf.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -3.5365 -1.8682 0.2772 1.2493 4.1589
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 150.87925 124.06427 1.216 0.243
#> x1 4.15688 3.11251 1.336 0.202
#> x2 -3.64609 3.11348 -1.171 0.260
#> x3 -2.45340 1.72707 -1.421 0.176
#> x1:x2 0.01401 0.02911 0.481 0.637
#>
#> Residual standard error: 2.542 on 15 degrees of freedom
#> Multiple R-squared: 0.8044, Adjusted R-squared: 0.7522
#> F-statistic: 15.42 on 4 and 15 DF, p-value: 3.41e-05
bf.data2 <- mutate( bf.data, x1x2= x1*x2)
BodyFat.Inter2=lm(y~ x1 + x2 + x3 + x1x2, data=bf.data2 )
summary(BodyFat.Inter2)
#>
#> Call:
#> lm(formula = y ~ x1 + x2 + x3 + x1x2, data = bf.data2)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -3.5365 -1.8682 0.2772 1.2493 4.1589
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 150.87925 124.06427 1.216 0.243
#> x1 4.15688 3.11251 1.336 0.202
#> x2 -3.64609 3.11348 -1.171 0.260
#> x3 -2.45340 1.72707 -1.421 0.176
#> x1x2 0.01401 0.02911 0.481 0.637
#>
#> Residual standard error: 2.542 on 15 degrees of freedom
#> Multiple R-squared: 0.8044, Adjusted R-squared: 0.7522
#> F-statistic: 15.42 on 4 and 15 DF, p-value: 3.41e-053.8 Standardized multiple regression
To compare the size of the estimated regression parameter estimates on a common scale, we have to standardize each variable (response and explanatory) in the model. Standardized multiple regression in R is illustrated using the Dwaine studios data:
require( mosaic )
### Import data:
url <- "http://www.csub.edu/~emontoya2/datasets/textbookdata/Kutner/Chapter%20%206%20Data%20Sets/CH06FI05.txt"
dwaine.data <- read.csv( url , header = FALSE , col.names = c("x1", "x2", "y") , sep = "" )
glimpse( dwaine.data )
#> Rows: 21
#> Columns: 3
#> $ x1 <dbl> 68.5, 45.2, 91.3, 47.8, 46.9, 66.1, 49.5, 52.0, 48.9, 38.4, 87.9, 7~
#> $ x2 <dbl> 16.7, 16.8, 18.2, 16.3, 17.3, 18.2, 15.9, 17.2, 16.6, 16.0, 18.3, 1~
#> $ y <dbl> 174.4, 164.4, 244.2, 154.6, 181.6, 207.5, 152.8, 163.2, 145.4, 137.~To standardize a given variable, we use a function called scale( ) within mutate:
require( mosaic )
### Standarize each explanatory variable using mutate()
### with scale().
dwaine.dataStdz <- mutate( dwaine.data , y.stdz = scale( y ) ,
x1.stdz = scale( x1) ,
x2.stdz = scale( x2 ) )
# The head( ) function allows one to view the
# first few observations of a given dataset.
# Note that we now have each standardize
# variable.
head( dwaine.dataStdz )
#> x1 x2 y y.stdz x1.stdz x2.stdz
#> 1 68.5 16.7 174.4 -0.20736368 0.3480579 -0.4563909
#> 2 45.2 16.8 164.4 -0.48367315 -0.9032627 -0.3533349
#> 3 91.3 18.2 244.2 1.72127642 1.5725261 1.0894493
#> 4 47.8 16.3 154.6 -0.75445643 -0.7636303 -0.8686150
#> 5 46.9 17.3 181.6 -0.00842086 -0.8119646 0.1619452
#> 6 66.1 18.2 207.5 0.70722067 0.2191665 1.0894493
dwaine.fitStdz <- lm( y.stdz ~ x1.stdz + x2.stdz -1, data= dwaine.dataStdz)
summary(dwaine.fitStdz)
#>
#> Call:
#> lm(formula = y.stdz ~ x1.stdz + x2.stdz - 1, data = dwaine.dataStdz)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.50907 -0.17176 0.02058 0.26071 0.55856
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> x1.stdz 0.7484 0.1061 7.056 1.03e-06 ***
#> x2.stdz 0.2511 0.1061 2.368 0.0287 *
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.296 on 19 degrees of freedom
#> Multiple R-squared: 0.9167, Adjusted R-squared: 0.908
#> F-statistic: 104.6 on 2 and 19 DF, p-value: 5.544e-11The output of summary(dwaine.fitStdz) is nearly identical to summary(dwaine.fit) but we now have the estimated standardized regression coefficient estimates, \(b_i^*\).
3.9 Polynomial regression and regression with categorical variables
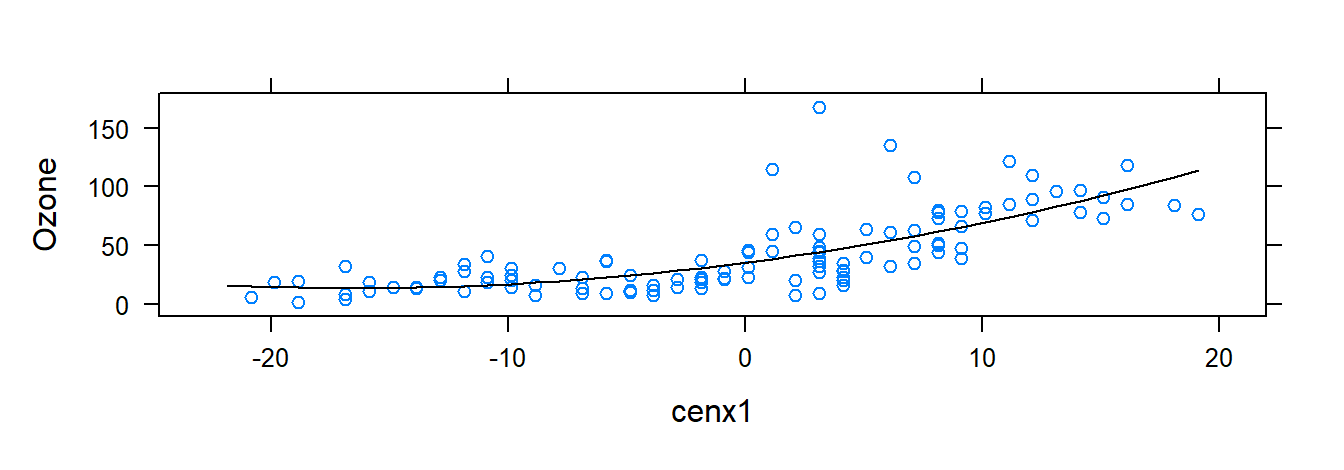
In this section, we start by using R to fit the second-order polynomial regression model with one predictor variable: \[ y_i=\beta_0 + \beta_1 x_{i}^* + \beta_1 x_i^{*2} + \varepsilon_i \] where \(x_{i}^* = x_i - \bar{x}\).
We fit this polynomial model using New York air quality measurements provided in the airquality dataset. In this illustration, the response is ozone and the explanatory variable is temperature. To start, center the explanatory variable and square the centered explanatory variable:
require( mosaic )
data( airquality )
glimpse( airquality )
#> Rows: 153
#> Columns: 6
#> $ Ozone <int> 41, 36, 12, 18, NA, 28, 23, 19, 8, NA, 7, 16, 11, 14, 18, 14, ~
#> $ Solar.R <int> 190, 118, 149, 313, NA, NA, 299, 99, 19, 194, NA, 256, 290, 27~
#> $ Wind <dbl> 7.4, 8.0, 12.6, 11.5, 14.3, 14.9, 8.6, 13.8, 20.1, 8.6, 6.9, 9~
#> $ Temp <int> 67, 72, 74, 62, 56, 66, 65, 59, 61, 69, 74, 69, 66, 68, 58, 64~
#> $ Month <int> 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,~
#> $ Day <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18,~
# center the explanatory variable and square the
# centered explanatory variable
airqualityCen <- mutate( airquality, cenx1 =scale( Temp , scale=FALSE ), cenx1sq = cenx1^2 )A polynomial regression is a linear regression model, so we fit the model in the same manner as past models:
require( mosaic )
polyfit <- lm( Ozone~ cenx1 + cenx1sq , data= airqualityCen )
# summarize the fit
summary( polyfit )
#>
#> Call:
#> lm(formula = Ozone ~ cenx1 + cenx1sq, data = airqualityCen)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -37.619 -12.513 -2.736 9.676 123.909
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 35.19617 2.79472 12.594 < 2e-16 ***
#> cenx1 2.60963 0.22610 11.542 < 2e-16 ***
#> cenx1sq 0.07807 0.02086 3.743 0.000288 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 22.47 on 113 degrees of freedom
#> (37 observations deleted due to missingness)
#> Multiple R-squared: 0.5442, Adjusted R-squared: 0.5362
#> F-statistic: 67.46 on 2 and 113 DF, p-value: < 2.2e-16
xyplot( Ozone ~ cenx1 , data = airqualityCen, panel = function(x, y, ...){
panel.xyplot(x, y, ...)
fm <- lm(y ~ poly(x, 2))
panel.lines(sort(x), predict(fm, newdata=data.frame( x=sort(x))), col.line = "black")
} )
3.10 Model selection
This section deals with different criteria for model selection for MLR. To illustrate different model selection criteria with R, we follow the Surgical Unit Example from ALRM. To start, import the data:
url <- "http://www.csub.edu/~emontoya2/datasets/textbookdata/Kutner/Chapter%20%209%20Data%20Sets/CH09TA01.txt"
surgunit.data <- read.csv( url , header = FALSE , col.names = c("x1", "x2", "x3", "x4", "x5", "x6", "x7", "x8", "y", "lny") , sep = "" )
glimpse( surgunit.data )
#> Rows: 54
#> Columns: 10
#> $ x1 <dbl> 6.7, 5.1, 7.4, 6.5, 7.8, 5.8, 5.7, 3.7, 6.0, 3.7, 6.3, 6.7, 5.8, 5~
#> $ x2 <int> 62, 59, 57, 73, 65, 38, 46, 68, 67, 76, 84, 51, 96, 83, 62, 74, 85~
#> $ x3 <int> 81, 66, 83, 41, 115, 72, 63, 81, 93, 94, 83, 43, 114, 88, 67, 68, ~
#> $ x4 <dbl> 2.59, 1.70, 2.16, 2.01, 4.30, 1.42, 1.91, 2.57, 2.50, 2.40, 4.13, ~
#> $ x5 <int> 50, 39, 55, 48, 45, 65, 49, 69, 58, 48, 37, 57, 63, 52, 58, 64, 36~
#> $ x6 <int> 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1, ~
#> $ x7 <int> 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, ~
#> $ x8 <int> 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, ~
#> $ y <int> 695, 403, 710, 349, 2343, 348, 518, 749, 1056, 968, 745, 257, 1573~
#> $ lny <dbl> 6.544, 5.999, 6.565, 5.854, 7.759, 5.852, 6.250, 6.619, 6.962, 6.8~Tell R that certain varialbes are categorical:
surgunit.data <- mutate( surgunit.data, x6fac =as.factor(x6), x7fac = as.factor( x7 ), x8fac= as.factor( x8 ) )
glimpse( surgunit.data )
#> Rows: 54
#> Columns: 13
#> $ x1 <dbl> 6.7, 5.1, 7.4, 6.5, 7.8, 5.8, 5.7, 3.7, 6.0, 3.7, 6.3, 6.7, 5.8,~
#> $ x2 <int> 62, 59, 57, 73, 65, 38, 46, 68, 67, 76, 84, 51, 96, 83, 62, 74, ~
#> $ x3 <int> 81, 66, 83, 41, 115, 72, 63, 81, 93, 94, 83, 43, 114, 88, 67, 68~
#> $ x4 <dbl> 2.59, 1.70, 2.16, 2.01, 4.30, 1.42, 1.91, 2.57, 2.50, 2.40, 4.13~
#> $ x5 <int> 50, 39, 55, 48, 45, 65, 49, 69, 58, 48, 37, 57, 63, 52, 58, 64, ~
#> $ x6 <int> 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1~
#> $ x7 <int> 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1~
#> $ x8 <int> 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0~
#> $ y <int> 695, 403, 710, 349, 2343, 348, 518, 749, 1056, 968, 745, 257, 15~
#> $ lny <dbl> 6.544, 5.999, 6.565, 5.854, 7.759, 5.852, 6.250, 6.619, 6.962, 6~
#> $ x6fac <fct> 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 1, 0, 0, 1~
#> $ x7fac <fct> 1, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1~
#> $ x8fac <fct> 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0~3.10.1 \(R_{a,p}^2\) and \(C_p\)
\(R^2\) does not decrease as the number of covariates in the model increases. The adjusted coefficient of determination, \(R_{a,p}^2\) may decrease as the number of covariates in the model increases, and so takes into account the number of explanatory variables that are in the model. To compute \(R_{a,p}^2\) for several candidate models, we use the function leaps function from the leaps R package. First install the R package leaps:
require( leaps )First, we have to define a matrix whose columns consist of the variables under consideration (this is not the design/model matrix). Note that leaps() can only handle factor variables with two levels and they must be numeric (don’t use the factored versions of \(x6\), \(x7\), and \(x8\):
Xleaps <- select( surgunit.data, -c( 9, 10, 11, 12, 13 ) ) The leaps() function requires this matrix, the response variable and the model selection criterion ("Cp" or "adjr2"):
R2adj.temp <- leaps(x=Xleaps, y=surgunit.data$"lny", method="adjr2")To better organize the information provided by leaps(), run the following:
#obtain relevant info
R2adj.info=cbind(R2adj.temp$which,R2adj.temp$size,R2adj.temp$adjr2)
# add names to make it easier to read info
colnames(R2adj.info)=c("x1","x2","x3","x4","x5", "x6", "x7", "x8", "p","adjr2")
R2adj.info
#> x1 x2 x3 x4 x5 x6 x7 x8 p adjr2
#> 1 0 0 1 0 0 0 0 0 2 0.416557881
#> 1 0 0 0 1 0 0 0 0 2 0.410417798
#> 1 0 1 0 0 0 0 0 0 2 0.205862939
#> 1 0 0 0 0 0 0 0 1 2 0.122406556
#> 1 1 0 0 0 0 0 0 0 2 0.042543244
#> 1 0 0 0 0 0 1 0 0 2 0.035653717
#> 1 0 0 0 0 1 0 0 0 2 0.002187716
#> 1 0 0 0 0 0 0 1 0 2 -0.002898254
#> 2 0 1 1 0 0 0 0 0 3 0.650085544
#> 2 0 0 1 1 0 0 0 0 3 0.583777218
#> 2 1 0 1 0 0 0 0 0 3 0.530934014
#> 2 0 0 1 0 0 0 0 1 3 0.497419295
#> 2 0 0 0 1 0 0 0 1 3 0.488519841
#> 2 0 1 0 1 0 0 0 0 3 0.462691631
#> 2 0 0 1 0 0 1 0 0 3 0.426095576
#> 2 0 0 1 0 1 0 0 0 3 0.424491387
#> 2 0 0 0 1 0 0 1 0 3 0.411731492
#> 2 0 0 1 0 0 0 1 0 3 0.410390386
#> 3 0 1 1 0 0 0 0 1 4 0.764715749
#> 3 1 1 1 0 0 0 0 0 4 0.742729360
#> 3 0 1 1 1 0 0 0 0 4 0.700885337
#> 3 0 1 1 0 0 0 1 0 4 0.661818074
#> 3 0 1 1 0 1 0 0 0 4 0.656711027
#> 3 0 1 1 0 0 1 0 0 4 0.649910695
#> 3 0 0 1 1 0 0 0 1 4 0.649267958
#> 3 1 0 1 1 0 0 0 0 4 0.588850588
#> 3 0 0 1 1 0 0 1 0 4 0.581680554
#> 3 0 0 1 1 1 0 0 0 4 0.577651443
#> 4 1 1 1 0 0 0 0 1 5 0.815996984
#> 4 0 1 1 1 0 0 0 1 5 0.799293694
#> 4 0 1 1 0 0 1 0 1 5 0.771518218
#> 4 0 1 1 0 1 0 0 1 5 0.765894154
#> 4 0 1 1 0 0 0 1 1 5 0.761994941
#> 4 1 1 1 0 1 0 0 0 5 0.750009741
#> 4 1 1 1 0 0 0 1 0 5 0.747435371
#> 4 1 1 1 0 0 1 0 0 5 0.741872034
#> 4 1 1 1 1 0 0 0 0 5 0.739554570
#> 4 0 1 1 1 0 0 1 0 5 0.711129897
#> 5 1 1 1 0 0 1 0 1 6 0.820508061
#> 5 1 1 1 0 1 0 0 1 6 0.818704958
#> 5 1 1 1 1 0 0 0 1 6 0.815758658
#> 5 1 1 1 0 0 0 1 1 6 0.814141607
#> 5 0 1 1 1 0 1 0 1 6 0.798911508
#> 5 0 1 1 1 0 0 1 1 6 0.796775100
#> 5 0 1 1 1 1 0 0 1 6 0.796460487
#> 5 0 1 1 0 1 1 0 1 6 0.772967184
#> 5 0 1 1 0 0 1 1 1 6 0.768818413
#> 5 0 1 1 0 1 0 1 1 6 0.764075717
#> 6 1 1 1 0 1 1 0 1 7 0.823449402
#> 6 1 1 1 0 0 1 1 1 7 0.818660139
#> 6 1 1 1 1 0 1 0 1 7 0.818132982
#> 6 1 1 1 0 1 0 1 1 7 0.817824375
#> 6 1 1 1 1 1 0 0 1 7 0.816356244
#> 6 1 1 1 1 0 0 1 1 7 0.813704868
#> 6 0 1 1 1 0 1 1 1 7 0.796331530
#> 6 0 1 1 1 1 1 0 1 7 0.796311668
#> 6 0 1 1 1 1 0 1 1 7 0.794252288
#> 6 0 1 1 0 1 1 1 1 7 0.771189602
#> 7 1 1 1 0 1 1 1 1 8 0.822597377
#> 7 1 1 1 1 1 1 0 1 8 0.819816836
#> 7 1 1 1 1 0 1 1 1 8 0.816097625
#> 7 1 1 1 1 1 0 1 1 8 0.815143680
#> 7 0 1 1 1 1 1 1 1 8 0.794098517
#> 7 1 1 1 1 1 1 1 0 8 0.746632006
#> 7 1 0 1 1 1 1 1 1 8 0.634657905
#> 7 1 1 0 1 1 1 1 1 8 0.553658658
#> 8 1 1 1 1 1 1 1 1 9 0.818773720Note that the models with among the higher \(R_{a,p}^2\) are the models that include \(x1\), \(x2\), \(x3\), and \(x8\) and include \(x1\), \(x2\), \(x3\), \(x6\), and \(x8\).
Mallows’ \(C_p\) criterion may also be obtained in the sammer manner using leaps but we replace "adjr2" with "Cp":
Cp.temp <- leaps(x=Xleaps, y=surgunit.data$"lny", method="Cp")
#obtain relevant info
Cp.info=cbind(Cp.temp$which,Cp.temp$size,Cp.temp$Cp)
# add names to make it easier to read info
colnames(Cp.info)=c("x1","x2","x3","x4","x5", "x6", "x7", "x8", "p","Cp")
Cp.info
#> x1 x2 x3 x4 x5 x6 x7 x8 p Cp
#> 1 0 0 1 0 0 0 0 0 2 117.409441
#> 1 0 0 0 1 0 0 0 0 2 119.171240
#> 1 0 1 0 0 0 0 0 0 2 177.865004
#> 1 0 0 0 0 0 0 0 1 2 201.811487
#> 1 1 0 0 0 0 0 0 0 2 224.726995
#> 1 0 0 0 0 0 1 0 0 2 226.703835
#> 1 0 0 0 0 1 0 0 0 2 236.306372
#> 1 0 0 0 0 0 0 1 0 2 237.765710
#> 2 0 1 1 0 0 0 0 0 3 50.471575
#> 2 0 0 1 1 0 0 0 0 3 69.131808
#> 2 1 0 1 0 0 0 0 0 3 84.002738
#> 2 0 0 1 0 0 0 0 1 3 93.434321
#> 2 0 0 0 1 0 0 0 1 3 95.938771
#> 2 0 1 0 1 0 0 0 0 3 103.207247
#> 2 0 0 1 0 0 1 0 0 3 113.505967
#> 2 0 0 1 0 1 0 0 0 3 113.957411
#> 2 0 0 0 1 0 0 1 0 3 117.548252
#> 2 0 0 1 0 0 0 1 0 3 117.925661
#> 3 0 1 1 0 0 0 0 1 4 18.914496
#> 3 1 1 1 0 0 0 0 0 4 24.980500
#> 3 0 1 1 1 0 0 0 0 4 36.525190
#> 3 0 1 1 0 0 0 1 0 4 47.303776
#> 3 0 1 1 0 1 0 0 0 4 48.712801
#> 3 0 1 1 0 0 1 0 0 4 50.589000
#> 3 0 0 1 1 0 0 0 1 4 50.766330
#> 3 1 0 1 1 0 0 0 0 4 67.435372
#> 3 0 0 1 1 0 0 1 0 4 69.413572
#> 3 0 0 1 1 1 0 0 0 4 70.525196
#> 4 1 1 1 0 0 0 0 1 5 5.750774
#> 4 0 1 1 1 0 0 0 1 5 10.267014
#> 4 0 1 1 0 0 1 0 1 5 17.776952
#> 4 0 1 1 0 1 0 0 1 5 19.297588
#> 4 0 1 1 0 0 0 1 1 5 20.351858
#> 4 1 1 1 0 1 0 0 0 5 23.592419
#> 4 1 1 1 0 0 0 1 0 5 24.288478
#> 4 1 1 1 0 0 1 0 0 5 25.792694
#> 4 1 1 1 1 0 0 0 0 5 26.419290
#> 4 0 1 1 1 0 0 1 0 5 34.104759
#> 5 1 1 1 0 0 1 0 1 6 5.540639
#> 5 1 1 1 0 1 0 0 1 6 6.018212
#> 5 1 1 1 1 0 0 0 1 6 6.798576
#> 5 1 1 1 0 0 0 1 1 6 7.226872
#> 5 0 1 1 1 0 1 0 1 6 11.260750
#> 5 0 1 1 1 0 0 1 1 6 11.826604
#> 5 0 1 1 1 1 0 0 1 6 11.909933
#> 5 0 1 1 0 1 1 0 1 6 18.132422
#> 5 0 1 1 0 0 1 1 1 6 19.231275
#> 5 0 1 1 0 1 0 1 1 6 20.487436
#> 6 1 1 1 0 1 1 0 1 7 5.787389
#> 6 1 1 1 0 0 1 1 1 7 7.029456
#> 6 1 1 1 1 0 1 0 1 7 7.166172
#> 6 1 1 1 0 1 0 1 1 7 7.246207
#> 6 1 1 1 1 1 0 0 1 7 7.626958
#> 6 1 1 1 1 0 0 1 1 7 8.314578
#> 6 0 1 1 1 0 1 1 1 7 12.820254
#> 6 0 1 1 1 1 1 0 1 7 12.825405
#> 6 0 1 1 1 1 0 1 1 7 13.359493
#> 6 0 1 1 0 1 1 1 1 7 19.340669
#> 7 1 1 1 0 1 1 1 1 8 7.029455
#> 7 1 1 1 1 1 1 0 1 8 7.735230
#> 7 1 1 1 1 0 1 1 1 8 8.679263
#> 7 1 1 1 1 1 0 1 1 8 8.921400
#> 7 0 1 1 1 1 1 1 1 8 14.263216
#> 7 1 1 1 1 1 1 1 0 8 26.311466
#> 7 1 0 1 1 1 1 1 1 8 54.733440
#> 7 1 1 0 1 1 1 1 1 8 75.293181
#> 8 1 1 1 1 1 1 1 1 9 9.000000Note that a model with \(x1\), \(x2\), \(x3\), \(x5\), and \(x8\) has a \(C_p\) that is near and above \(p\).
3.10.2 \(AIC_p\)
The AIC criterion may be computed using the funciton AIC(). The only argument for this funciton is an lm object. For example:
3.10.3 \(BIC_p\) or \(SBC_p\)
The BIC criterion may be computed using the function AIC() as well but we have to add an additional argument:
dim(surgunit.data)
#> [1] 54 13
AIC( fit1, fit2, fit3 , k= log( 54 ))
#> df AIC
#> fit1 7 5.902830
#> fit2 6 3.827912
#> fit3 7 52.372440Note that by default, \(k=2\).
3.10.4 \(AICc_p\)
Akaike’s corrected Information Criterion may also be computed with AIC() by adding the “correction”:
# get AIC of a model and store result
storeAIC <- AIC( fit1, fit2, fit3 )
AICc <- storeAIC$AIC + ( 2*(storeAIC$df)^2 + 2*storeAIC$df ) / ( 54- storeAIC$df -1)
AICc
#> [1] -5.585275 -6.318758 40.884335
storeBIC <- AIC( fit1, fit2, fit3, k=log(54) )
cbind(AICc, storeAIC, storeBIC) #ignore the column headers
#> AICc df AIC df AIC
#> fit1 -5.585275 7 -8.020058 7 5.902830
#> fit2 -6.318758 6 -8.105992 6 3.827912
#> fit3 40.884335 7 38.449552 7 52.3724403.10.5 Stepwise regression
The function step() in R performs forward and backward stepwise regression. The step() function uses AIC (by default) for its model selection criterion. The arguments of the step function are the initial model (an lm object) to start the procedure, the scope (the covariates under consideration), and the direction of the search (backward or forward)
Forward selection starts with a model with no explanatory variables and decides which covariates to add at each step by getting the explanatory variables that gives the lowest AIC, if in the next step a lower AIC is not obtained, then it stops searching. Therefore, the model to specify in step() must be a model with just the intercept and the scope must include all the predictor variables to include in the search. We demonstrate with the Surgical
Unit data but we limit ourselves for using the first 4 predictor variables as before for the purpose of illustration:
fit0 <- lm(lny ~ 1, data= surgunit.data) #model with just the intercept
# using AIC criterion
fit.fstepAIC <- step(fit0, scope=~ x1+x2+x3+x4, direction="forward" )
#> Start: AIC=-75.7
#> lny ~ 1
#>
#> Df Sum of Sq RSS AIC
#> + x3 1 5.4762 7.3316 -103.827
#> + x4 1 5.3990 7.4087 -103.262
#> + x2 1 2.8285 9.9792 -87.178
#> + x1 1 0.7763 12.0315 -77.079
#> <none> 12.8077 -75.703
#>
#> Step: AIC=-103.83
#> lny ~ x3
#>
#> Df Sum of Sq RSS AIC
#> + x2 1 3.0191 4.3125 -130.48
#> + x4 1 2.2019 5.1297 -121.11
#> + x1 1 1.5506 5.7810 -114.66
#> <none> 7.3316 -103.83
#>
#> Step: AIC=-130.48
#> lny ~ x3 + x2
#>
#> Df Sum of Sq RSS AIC
#> + x1 1 1.20395 3.1085 -146.16
#> + x4 1 0.69836 3.6141 -138.02
#> <none> 4.3125 -130.48
#>
#> Step: AIC=-146.16
#> lny ~ x3 + x2 + x1
#>
#> Df Sum of Sq RSS AIC
#> <none> 3.1085 -146.16
#> + x4 1 0.024578 3.0840 -144.59
# model suggested by forward selection w/AIC
summary(fit.fstepAIC)
#>
#> Call:
#> lm(formula = lny ~ x3 + x2 + x1, data = surgunit.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.46992 -0.17954 -0.03071 0.17883 0.59253
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 3.766176 0.226758 16.609 < 2e-16 ***
#> x3 0.016452 0.001630 10.094 1.17e-13 ***
#> x2 0.013340 0.002035 6.556 2.97e-08 ***
#> x1 0.095458 0.021692 4.401 5.67e-05 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2493 on 50 degrees of freedom
#> Multiple R-squared: 0.7573, Adjusted R-squared: 0.7427
#> F-statistic: 52 on 3 and 50 DF, p-value: 2.124e-15Now obtain results using the forward stepwise regression results using the BIC criterion:
# using BIC criterion --> note the argument k= log(n)
fit.fstepBIC <- step(fit0, scope=~ x1+x2+x3+x4, direction="forward" , k= log(54) )
#> Start: AIC=-73.71
#> lny ~ 1
#>
#> Df Sum of Sq RSS AIC
#> + x3 1 5.4762 7.3316 -99.849
#> + x4 1 5.3990 7.4087 -99.284
#> + x2 1 2.8285 9.9792 -83.200
#> <none> 12.8077 -73.714
#> + x1 1 0.7763 12.0315 -73.101
#>
#> Step: AIC=-99.85
#> lny ~ x3
#>
#> Df Sum of Sq RSS AIC
#> + x2 1 3.0191 4.3125 -124.516
#> + x4 1 2.2019 5.1297 -115.146
#> + x1 1 1.5506 5.7810 -108.691
#> <none> 7.3316 -99.849
#>
#> Step: AIC=-124.52
#> lny ~ x3 + x2
#>
#> Df Sum of Sq RSS AIC
#> + x1 1 1.20395 3.1085 -138.21
#> + x4 1 0.69836 3.6141 -130.07
#> <none> 4.3125 -124.52
#>
#> Step: AIC=-138.2
#> lny ~ x3 + x2 + x1
#>
#> Df Sum of Sq RSS AIC
#> <none> 3.1085 -138.21
#> + x4 1 0.024578 3.0840 -134.65
# model suggested by forward selection w/AIC
summary(fit.fstepBIC)
#>
#> Call:
#> lm(formula = lny ~ x3 + x2 + x1, data = surgunit.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.46992 -0.17954 -0.03071 0.17883 0.59253
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 3.766176 0.226758 16.609 < 2e-16 ***
#> x3 0.016452 0.001630 10.094 1.17e-13 ***
#> x2 0.013340 0.002035 6.556 2.97e-08 ***
#> x1 0.095458 0.021692 4.401 5.67e-05 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2493 on 50 degrees of freedom
#> Multiple R-squared: 0.7573, Adjusted R-squared: 0.7427
#> F-statistic: 52 on 3 and 50 DF, p-value: 2.124e-15Backward selection starts with a full model with all predictors and it decides which predictor to delete at each step by seeing which predictor deletion leads to the lowest AIC, once a lower AIC is
not obtained in the next step it stops. Therefore the model to specify in step() must be a model with all the predictor variables and the scope must include all the predictor variables to include in
the search:
fitfull <- lm(lny ~ x1 + x2 + x3 + x4, data= surgunit.data) #model with just the intercept
# using AIC criterion
fit.BstepAIC <- step(fitfull, scope=~ x1+x2+x3+x4, direction="backward" )
#> Start: AIC=-144.59
#> lny ~ x1 + x2 + x3 + x4
#>
#> Df Sum of Sq RSS AIC
#> - x4 1 0.0246 3.1085 -146.16
#> <none> 3.0840 -144.59
#> - x1 1 0.5302 3.6141 -138.02
#> - x2 1 1.8839 4.9678 -120.84
#> - x3 1 3.4862 6.5702 -105.75
#>
#> Step: AIC=-146.16
#> lny ~ x1 + x2 + x3
#>
#> Df Sum of Sq RSS AIC
#> <none> 3.1085 -146.161
#> - x1 1 1.2040 4.3125 -130.483
#> - x2 1 2.6724 5.7810 -114.658
#> - x3 1 6.3341 9.4427 -88.162
# model suggested by forward selection w/AIC
summary(fit.BstepAIC)
#>
#> Call:
#> lm(formula = lny ~ x1 + x2 + x3, data = surgunit.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.46992 -0.17954 -0.03071 0.17883 0.59253
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 3.766176 0.226758 16.609 < 2e-16 ***
#> x1 0.095458 0.021692 4.401 5.67e-05 ***
#> x2 0.013340 0.002035 6.556 2.97e-08 ***
#> x3 0.016452 0.001630 10.094 1.17e-13 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2493 on 50 degrees of freedom
#> Multiple R-squared: 0.7573, Adjusted R-squared: 0.7427
#> F-statistic: 52 on 3 and 50 DF, p-value: 2.124e-15Now obtain results using the backward stepwise regression results using the BIC criterion:
# using BIC criterion --> note the argument k= log(n)
fit.BstepBIC <- step(fitfull, scope=~ x1+x2+x3+x4, direction="backward" , k= log(54) )
#> Start: AIC=-134.64
#> lny ~ x1 + x2 + x3 + x4
#>
#> Df Sum of Sq RSS AIC
#> - x4 1 0.0246 3.1085 -138.205
#> <none> 3.0840 -134.645
#> - x1 1 0.5302 3.6141 -130.067
#> - x2 1 1.8839 4.9678 -112.888
#> - x3 1 3.4862 6.5702 -97.792
#>
#> Step: AIC=-138.2
#> lny ~ x1 + x2 + x3
#>
#> Df Sum of Sq RSS AIC
#> <none> 3.1085 -138.205
#> - x1 1 1.2040 4.3125 -124.516
#> - x2 1 2.6724 5.7810 -108.691
#> - x3 1 6.3341 9.4427 -82.195
# model suggested by forward selection w/AIC
summary(fit.BstepBIC)
#>
#> Call:
#> lm(formula = lny ~ x1 + x2 + x3, data = surgunit.data)
#>
#> Residuals:
#> Min 1Q Median 3Q Max
#> -0.46992 -0.17954 -0.03071 0.17883 0.59253
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 3.766176 0.226758 16.609 < 2e-16 ***
#> x1 0.095458 0.021692 4.401 5.67e-05 ***
#> x2 0.013340 0.002035 6.556 2.97e-08 ***
#> x3 0.016452 0.001630 10.094 1.17e-13 ***
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.2493 on 50 degrees of freedom
#> Multiple R-squared: 0.7573, Adjusted R-squared: 0.7427
#> F-statistic: 52 on 3 and 50 DF, p-value: 2.124e-153.10.6 CV/PRESS and GCV
The cross validation (CV) or PRESS criterion provides a sense of how well the model can predict new values of y. We use the computational friendly from the CV criterion to compute a CV scores. To illustrate, the CV scores of fit1, fit2, and fit3 are computed.
n <- 54
### CV score fit1
cvtop <- residuals( fit1 )
# diagonal elements of the hat matrix: h_ii's
cvbottom <- 1- hatvalues( fit1 )
# CV score
CVfit1 <- 1/n*sum( (cvtop/cvbottom)^2 )
###
###
### CV score fit2
cvtop <- residuals( fit2 )
# hatvalues # <--- provides the diagonal elements of H
cvbottom <- 1- hatvalues( fit2 )
# CV score
CVfit2 <- 1/n*sum( (cvtop/cvbottom)^2 )
###
###
### CV score fit3
cvtop <- residuals( fit3 )
# diagonal elements of the hat matrix: h_ii's
# hatvalues # <--- provides the diagonal elements of H
cvbottom <- 1- hatvalues( fit3 )
# CV score
CVfit3 <- 1/n*sum( (cvtop/cvbottom)^2 )
###
###
CVfit1
#> [1] 0.05072096
CVfit2
#> [1] 0.05069947
CVfit3
#> [1] 0.1158974Next, compute the GCV scores:
n <- 54
### GCV score fit1
### sum of squared residuals
SSE <- sum( residuals( fit1 )^2 )
gcvbottom <- ( 1- mean( hatvalues( fit1 ) ) )^2
# GCV score
gcvfit1 <- 1/n*( SSE/gcvbottom )
###
###
### GCV score fit2
### sum of squared residuals
SSE <- sum( residuals( fit2 )^2 )
gcvbottom <- ( 1- mean( hatvalues( fit2 ) ) )^2
# GCV score
gcvfit2 <- 1/n*( SSE/gcvbottom )
###
###
### GCV score fit2
### sum of squared residuals
SSE <- sum( residuals( fit3 )^2 )
gcvbottom <- ( 1- mean( hatvalues( fit3 ) ) )^2
# GCV score
gcvfit3 <- 1/n*( SSE/gcvbottom )
###
###
gcvfit1
#> [1] 0.04928725
gcvfit2
#> [1] 0.04900256
gcvfit3
#> [1] 0.11653763.11 More diagnostics
3.11.1 Identifying outlying y and x values
The body fat example is used to illustrate studentized residuals, deleted residuals, and studentized deleted residuals. To start, import the data:
### Import data:
url <- "https://www.csub.edu/~emontoya2/datasets/textbookdata/Kutner/Chapter%20%207%20Data%20Sets/CH07TA01.txt"
### This is not a .csv file and the file does not
### include variable names, so some changes
### have to be made to read.csv().
bf.data <- read.csv( url , header = FALSE , col.names = c( "x1", "x2", "x3", "y" ) , sep = "" )
glimpse( bf.data )
#> Rows: 20
#> Columns: 4
#> $ x1 <dbl> 19.5, 24.7, 30.7, 29.8, 19.1, 25.6, 31.4, 27.9, 22.1, 25.5, 31.1, 3~
#> $ x2 <dbl> 43.1, 49.8, 51.9, 54.3, 42.2, 53.9, 58.5, 52.1, 49.9, 53.5, 56.6, 5~
#> $ x3 <dbl> 29.1, 28.2, 37.0, 31.1, 30.9, 23.7, 27.6, 30.6, 23.2, 24.8, 30.0, 2~
#> $ y <dbl> 11.9, 22.8, 18.7, 20.1, 12.9, 21.7, 27.1, 25.4, 21.3, 19.3, 25.4, 2~
#> Rows: 20
#> Columns: 4
#> $ x1 <dbl> 19.5, 24.7, 30.7, 29.8, 19.1, 25.6, 31.4, 27.9, 22.1, 25.5, 31.1, 3~
#> $ x2 <dbl> 43.1, 49.8, 51.9, 54.3, 42.2, 53.9, 58.5, 52.1, 49.9, 53.5, 56.6, 5~
#> $ x3 <dbl> 29.1, 28.2, 37.0, 31.1, 30.9, 23.7, 27.6, 30.6, 23.2, 24.8, 30.0, 2~
#> $ y <dbl> 11.9, 22.8, 18.7, 20.1, 12.9, 21.7, 27.1, 25.4, 21.3, 19.3, 25.4, 2~Examine the scatterplot matrix for potential outlying values:
splom(bf.data)
To obtain the studentized residuals we use the function rstandard() whose only argument is an lm object:
fit1 <- lm( y ~ x1 + x2 + x3, data= bf.data)
# studentized residual
rstandard( fit1 )
#> 1 2 3 4 5 6
#> -1.46802633 1.13326956 -1.23262045 -1.29571232 0.57630252 -0.23525791
#> 7 8 9 10 11 12
#> 0.62249950 1.38022830 0.76529502 -0.57761774 0.34965240 0.94324119
#> 13 14 15 16 17 18
#> -1.50477923 1.84715613 0.49352568 0.07392664 -0.16107977 -0.63614383
#> 19 20
#> -1.61308352 0.25538013The function rstudent() obtains the studentized deleted residuals:
# studentized deleted residuals
rstudent( fit1 )
#> 1 2 3 4 5 6
#> -1.52803951 1.14416429 -1.25452990 -1.32606735 0.56388572 -0.22818249
#> 7 8 9 10 11 12
#> 0.61016668 1.42385079 0.75493974 -0.56519997 0.33985038 0.93979234
#> 13 14 15 16 17 18
#> -1.57251203 2.01637183 0.48153342 0.07159138 -0.15609143 -0.62388391
#> 19 20
#> -1.70680191 0.24777625The function hatvalues() obtains the influence or leverage values (\(h_ii's\)) :
# studentized deleted residuals
hatvalues( fit1 )
#> 1 2 3 4 5 6 7
#> 0.34120920 0.15653638 0.44042770 0.11242972 0.36109984 0.13151364 0.19433721
#> 8 9 10 11 12 13 14
#> 0.16418081 0.19278940 0.24051819 0.13935816 0.10929380 0.21357666 0.18808377
#> 15 16 17 18 19 20
#> 0.34830629 0.11439069 0.12532943 0.22828343 0.13235798 0.06597771
# note n is 20
# p is 4
3*4/20
#> [1] 0.6
xyplot( hatvalues( fit1 ) ~ 1:20 ,
panel = function(x, y) {
panel.xyplot(x, y)
panel.abline(a=3*4/20, b=0, col="red")
}, xlab = "Cases",
ylab = "Leverage values", ylim=c(0, .7))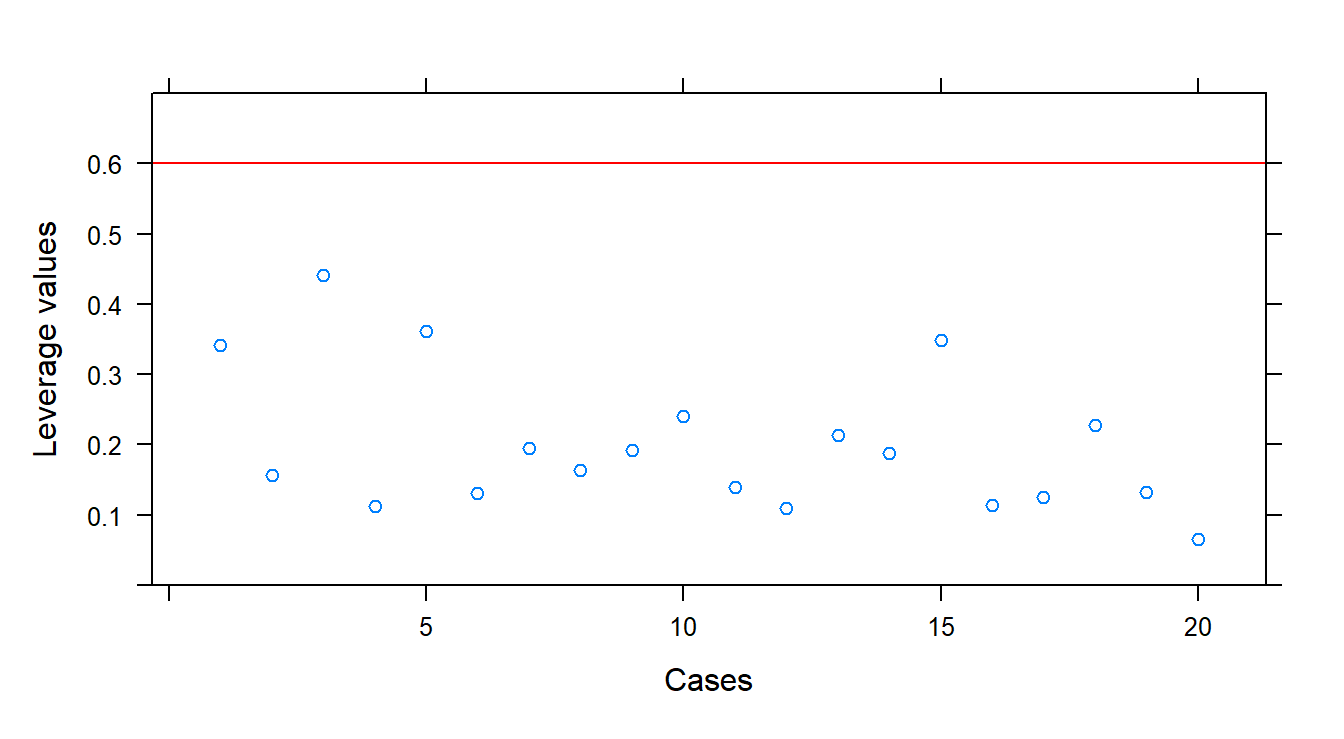
3.11.2 Identifying influential cases
The difference in fits for observation i (or DFFITS) can be obtained by using dffits() whose only argument is an lm object:
dffits( fit1 )
#> 1 2 3 4 5 6
#> -1.09969231 0.49290457 -1.11298735 -0.47195954 0.42392423 -0.08879453
#> 7 8 9 10 11 12
#> 0.29967452 0.63105834 0.36894399 -0.31806611 0.13675485 0.32920196
#> 13 14 15 16 17 18
#> -0.81948815 0.97048913 0.35203458 0.02572972 -0.05908583 -0.33932204
#> 19 20
#> -0.66663467 0.06585362
2*sqrt( (4+1)/(20-4-1))
#> [1] 1.154701
# plot DFFITS vs cases
xyplot( dffits( fit1 ) ~ 1:20 ,
panel = function(x, y) {
panel.xyplot(x, y)
panel.abline(a=1.154701, b=0, col="red")
},
xlab = "cases",
ylab = "DFFITS", ylim=c(0, 1.2) )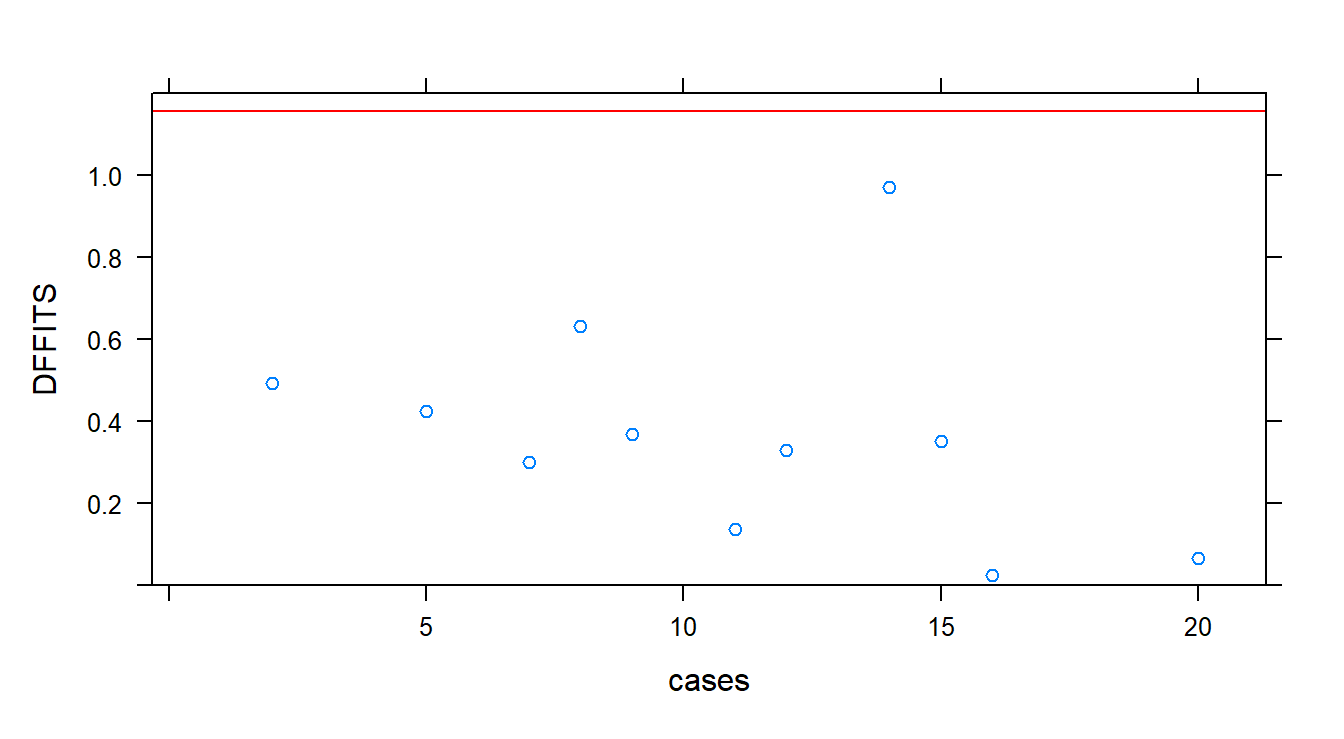
Cook’s distance measure is computed using cooks.distance() and it requires an lm object:
cooks.distance( fit1 )
#> 1 2 3 4 5 6
#> 0.2790492817 0.0595875286 0.2989628090 0.0531661934 0.0469283564 0.0020952519
#> 7 8 9 10 11 12
#> 0.0233679530 0.0935517519 0.0349698759 0.0264150596 0.0049490632 0.0272927035
#> 13 14 15 16 17 18
#> 0.1537386238 0.1976001749 0.0325444771 0.0001764779 0.0009294597 0.0299272765
#> 19 20
#> 0.0992346339 0.0011517393
# If D_i >> .5, it may be an influential point.
# If D_i >> 1, it quite likely to be an influential point.
xyplot( dffits( fit1 ) ~ 1:20 ,
panel = function(x, y) {
panel.xyplot(x, y)
panel.abline(a=c(.5), b=c(0), col="red")
panel.abline(a=c(1), b=c(0), col="blue")
},
xlab = "cases",
ylab = "Cooks distance", ylim=c(0, 1.2) )